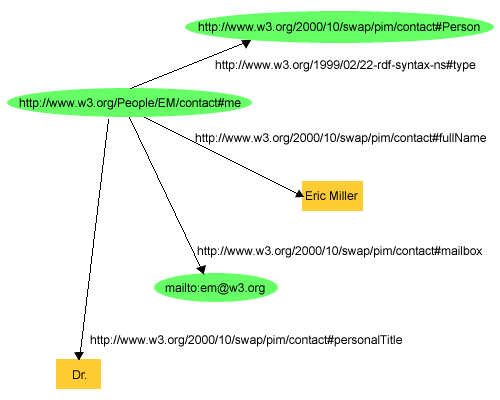
An example of a web standard RDF ontology from W3. org
The Corporate Semantic Ontology:
The straightforward way for employees to use the system is send the ontology pruner process any important charts, documents, agreements, anything digital. In the background, the key word extraction and document ontology are extracted. The best way to manage this is the cheapest, have employees keep a private company blog and use cut-n-paste. The blog posting is then convolved with the company ontology.
Give me an example of Shannon encoding on the ontology graph
Consider the tons of postings I have put out which few read, vs the few gems I post now and then which are popular. Well, under Shannon encoding, the unread posts should be moved to archives. What happened to the ontology graphs generated by these posts? Their semantic graph still exists, but since they are rarely triggered in a search, the graphs are preceded by the term, 'archive', making them disappear from normal retrievals. So, rare search results require longer semantic identifiers, more search terms. We are minimizing seldom selected results, minimizing redundancy or maximizing entropy.
That is where the staff of Imagisoft is on the project.
The diagram is compacted and fit into an XML file of text. The diagram above is a particular example of a net location map for public nformation, perhaps within a corporation. This particular graph, allows net processes running in the back ground, to locate virtual Eric for an newsletter subscription, for example. So here the web geeks are using ontology with XML to help computer processes automatically locate formatted text and photos some where on the company network, the system set up by the system administrator. But, ontology is just a tool, used for computer administration in thhis case.
The Corporate Semantic Ontology:
What we want is to use ontology as a tool to capture company semantics, Shannon encoded. The ontology maps we have in mind are not set up by network administrators, they are set up by computer processes themselves, looking over the collection of company documents. The company semantic is optimized to the rank and dimension of the ontology. Here dimension is the set size, the typical number of partially ordered, key terms that define a node on the ontology. Out ontology graphs, at the terminals, do hold URL strings.
Now, let me say, at this point, that in actual operation we generally do not want XML files, we want SQL records, retrieved in large blocks and hold nested order ontology graphs. These are extracted from SQL and put in DOM tree equivalents. Then we do convulation operations between segments for the graph to, well, think. (XML is used to migrate the ontology graphs around the net or display them )
When we say Shannon encoded, we want the search strings from clients, to yield sets of semantic strings in the company ontology that meet the -iLog(i) criteria. The background ontology pruner does just that. It looks at frequency of use vs specificity, just like a Huffman encoder. And since the object at the nodes is partially ordered, the ontology pruner can subtly knock of low order possible terms.
The straightforward way for employees to use the system is send the ontology pruner process any important charts, documents, agreements, anything digital. In the background, the key word extraction and document ontology are extracted. The best way to manage this is the cheapest, have employees keep a private company blog and use cut-n-paste. The blog posting is then convolved with the company ontology.
Give me an example of Shannon encoding on the ontology graph
Consider the tons of postings I have put out which few read, vs the few gems I post now and then which are popular. Well, under Shannon encoding, the unread posts should be moved to archives. What happened to the ontology graphs generated by these posts? Their semantic graph still exists, but since they are rarely triggered in a search, the graphs are preceded by the term, 'archive', making them disappear from normal retrievals. So, rare search results require longer semantic identifiers, more search terms. We are minimizing seldom selected results, minimizing redundancy or maximizing entropy.
That is where the staff of Imagisoft is on the project.
No comments:
Post a Comment