
. My gain function, the first factor, represent average signal for component i. The gamma character is the packing efficiency, the bits per cycles. The Ni should be nearly equal, differing by quantization error in each component.
This yield curve tries to measure itself as a normal distribution of growth rates, under the assumption that the given transaction rates are maximum entropy and the efficiency represents the variance of the constant SNR: Formally, given efficiency and a set of transaction rates, what are the transaction gains that complete the eigen system.
Update:
I will add estimators for my channel selection using the Maximum spacing method. Each channel have a pair (a,b) defining channel space on the curve. So the Vi sequence of tuned channels determined as the pair a,b the channel band limits. Threat them as uniform, then I close the system. But I need starter channels, or I self start with a channel search.
Like this R Code:
It set the bin sizes in a and histogram counts in xc. I can assume good bit efficiency so my band limits should be of the same size as my a,b pairs. My histogram counts tell me what is the lower to upper bands. Hence, I set ny vi in spectral estimaator and generate the yield curve, we hope.
ab <- function(d) {
dcount <<- dcount + 1
j <- 0
while (a[j+1] < d)
j <- j+1
x <- a[j]
y <- a[j+1]
xc[j] <<- xc[j]+1
n <- xc[j]
if(j > 0)
a[j] <- (n*x+d)/(n-1)
if(j < nmax)
a[j+1] <<- (n*y-d)/(n-1)
}
But I can normalize tmy hisoram across components with this method.
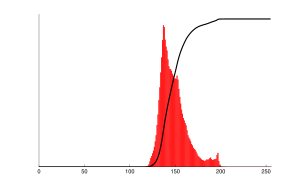
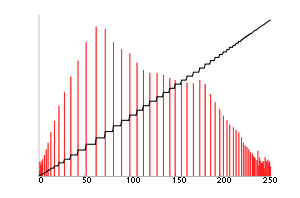
However, I can make the adjustments in the gain factor in my yield curve tuner, adding the histogram count. So the gain function has more than one representation depending upon the level of encoding already done in the data.
No comments:
Post a Comment