Everything is a graph named in the users local space, and everyone agrees wit that, essentially. There is and aklways has been he "right here", or the "rel" telative to here marker. We have that in real and Lazy J, in both cases, the syntax ends up starting with the name of a persistent Json. Either name: or name. or Name, or Name$ or however it is referenced or whatever method is implies the very first name in a syntax must be a table (or graph in non sql). So this all makes sense for the ugly handler in my engine, it takes the first element, and either finds the real table, or introduces the vitual table. The one exception to this default grammar rule is the doublet, as in Name:ImmediateValue which is detectable and makes a string entry into the local symbol table.
Then the client easily names his subject, everytime, they are the lists most familar to the client, using the clients own semantics. The predicate is the method chosen as either query or value modification. The Name:{list of new entries into my named able} easy, as is name.and_these_fields send back to requester. This is doable, on the case actually, almost working in the lab.
We gain great utility, but we lose access to local symbols, except via the hokey. Here is why: This form: textnote:"Drop this off in my note table"
That is going to be such a popular append, so we don't have this doublet concept, where the bund object is a single element. That goes away. So, go out of band to use the local table, work that later. Just the idea of simple syntax search and append/create is so compelling. It creates that very simple naming context around the sqlite3 table naming system. Remember, the marketing model is everyone has one of these, they are free. It is separate from their OS, blocked to quite a degree, and safe, But with a hugely simple Json between the browser, the upload file, tee query and tale formatted output. But built in naturally as an on line server, accessible from anywhere in the same format! It is vrtual, move it around the web, it retains its form.
Wednesday, February 29, 2012
Doing high speed appends with Sqlite3
While maintaining Qson nested format. Simple, the default init_table context will created pre-compiled statement to the table named. The process converts a Json package automatically to Qson in the parser. But all that is is append table, or append and update forward pointer. The engine just opens a table, pulls out the lead triplet whose bounded object is the entire table. But it is a bit difficult to do inserts, the whole or part of the Qson needs to unpack for insert. The preferred is a fast rewrite of the table. But streaming onto append, for regular word lists, regular tweets, memos, chats, or whatever, as long as the table has a natural array (Comma) ending, we should be fine with append.
But the Json parser can just as easily work with a memory based Qson, so the engine can parrse out to memory, then run and append against the data. It comes down to load three words, adn the lenth of the key value into sqlite3, it needs only find the next available row space,grab the key value, and return. Optimized B Trees look nice here. But is should be extremely fast, as fast as any Javascript could do, I would think. This is all very interesting to me.
But the Json parser can just as easily work with a memory based Qson, so the engine can parrse out to memory, then run and append against the data. It comes down to load three words, adn the lenth of the key value into sqlite3, it needs only find the next available row space,grab the key value, and return. Optimized B Trees look nice here. But is should be extremely fast, as fast as any Javascript could do, I would think. This is all very interesting to me.
Don't burn Crayons in Afghanistan
AFGHANS: QURAN-BURNING SOLDIERS TO FACE TRIAL
The US should distribute crayolas all over Afghanistan. Crayons good.
The US should distribute crayolas all over Afghanistan. Crayons good.
If I were head of Microsoft Windows
I would make a proprietary, Posix standard kernel, and guarantee every windows application run one on that kernel. I mean, use their marketing power to define the absolute standard in kernel, they put VMWare in a hole because the Windows kernel now runs Linux applications.
If I were feeling radical, I would think about releasing the Win32 GUI under open source, unmodifiable license. Then you really do have Windows everywhere, both the GUI and the kernel. Everyone writing to Posix would be writing to Microsoft Windows. Everyone building development and other frameworks with the Windows GUI would be writing to the Windows kernel. Get them from both ends, basically capture all the Linux desktops as frameworks. Open up the Windows to the server market in a big way, taking much of the linux kernel business.
If I were feeling radical, I would think about releasing the Win32 GUI under open source, unmodifiable license. Then you really do have Windows everywhere, both the GUI and the kernel. Everyone writing to Posix would be writing to Microsoft Windows. Everyone building development and other frameworks with the Windows GUI would be writing to the Windows kernel. Get them from both ends, basically capture all the Linux desktops as frameworks. Open up the Windows to the server market in a big way, taking much of the linux kernel business.
How does the machine help mobile users?
For one thing, the machine is a server, just dial in the ip to your mobile phone and pull out your bookmarks, or any other named Json bundle. Secondly, get some free table space on the web and keep your bookmarks on the web table space, perfectly secure, then just dial in the server and grab your stuff to the phone. Or like tweets, you can access public table space from your phone, in each cse you get a Json stream, and your phone browsers gets what to do.
But with everything organized as web wide named graphs, down to the null single element graph, the client jumps into any namespace of the moment. So his service provider, having one of these open source engines, keeps the table updated with the latest news, science, politics, entertainment, music, etc. The key values move slowly, the various indexes to them are arbitrarily nested or partitioned. We get huge warehouses of data,video,audio; more or less stuck in one spot, but a variety of nested indexing graphs, mobile users can dial in the name space they want; bots maintain maximum distribution of indices.
But with everything organized as web wide named graphs, down to the null single element graph, the client jumps into any namespace of the moment. So his service provider, having one of these open source engines, keeps the table updated with the latest news, science, politics, entertainment, music, etc. The key values move slowly, the various indexes to them are arbitrarily nested or partitioned. We get huge warehouses of data,video,audio; more or less stuck in one spot, but a variety of nested indexing graphs, mobile users can dial in the name space they want; bots maintain maximum distribution of indices.
High speed word list searching with sqlite3
Eveything is about Qson format, and so is this. Qson exist in memory in a very efficient form. Actually, Qson exists in two forms in memory, flat, ready for io and with separate key data. The latter is very efficient for lambda, if it is a small graph, like a search graph. So we create a call back match(keyvalue,keylen) Sqlite can use this and quickly get the row values for a Qson search word.
insert into resultselect * from tablename where match(key,length(key));
That form is compiled, with table name, let it run 10,000 names, not a problem. so:
bookmark."joe bob henry pat" becomes @bookmark,{joe,bob,henry,pat}
the later group in memory. The machine has to contain the default grammar in any case, it easily works half the equation from memory.Tables (graphs) whether square, qson, or hybrids; they all have their schema loaded into the table context. So, bookmark$name, as a query yields, in the @ variant: @bookmark,$name so schema names are loaded into the current runtime symbol set. Its expression is a combination of table type, and schema type. A bit of logic, but nothing a reckless programmer can't handle. Wer have schemas that specify everything is named, Qson already has a form for that. We have schema in which name can be converted into square col num, I have lab code for that. Nothing a 40 line if then can't handle!
Using these queries, and assuming local name space, we take some burden off of the old : ugly, the thing that makes value changes to name space entries, especially tables. Name: is a definition that gets resolved during a table run. We have a default, simple named form, a two triple bundle. We have, naturally, name:graph, where graph is a specific, nested subgraph, including theone immediately following. bookmark:{name:"joe".address:'anywhere'} is append to bookmark, in default, ok. $schema is correct in Json schema#, anyone notice? We have a new Ugly! Sure, that helps, though a default grammar, even context specific is preferable. So I will include the new ugly to make real tables, or make schema graph separately, and bind to a table of Qson, whatever makes sense.
Not a problem.
insert into resultselect * from tablename where match(key,length(key));
That form is compiled, with table name, let it run 10,000 names, not a problem. so:
bookmark."joe bob henry pat" becomes @bookmark,{joe,bob,henry,pat}
the later group in memory. The machine has to contain the default grammar in any case, it easily works half the equation from memory.Tables (graphs) whether square, qson, or hybrids; they all have their schema loaded into the table context. So, bookmark$name, as a query yields, in the @ variant: @bookmark,$name so schema names are loaded into the current runtime symbol set. Its expression is a combination of table type, and schema type. A bit of logic, but nothing a reckless programmer can't handle. Wer have schemas that specify everything is named, Qson already has a form for that. We have schema in which name can be converted into square col num, I have lab code for that. Nothing a 40 line if then can't handle!
Using these queries, and assuming local name space, we take some burden off of the old : ugly, the thing that makes value changes to name space entries, especially tables. Name: is a definition that gets resolved during a table run. We have a default, simple named form, a two triple bundle. We have, naturally, name:graph, where graph is a specific, nested subgraph, including theone immediately following. bookmark:{name:"joe".address:'anywhere'} is append to bookmark, in default, ok. $schema is correct in Json schema#, anyone notice? We have a new Ugly! Sure, that helps, though a default grammar, even context specific is preferable. So I will include the new ugly to make real tables, or make schema graph separately, and bind to a table of Qson, whatever makes sense.
Not a problem.
Anyway, software break is over, lets consider something
Like dropping a new bookmark onto the bookmark table. The machine, as it stands, would in the default just append the book mark table. Appending is a natural consequence of forward looking nested bound objects with skip ahead counts. So the Lazy Json is: bookmark{newname,newurl,..}. Running that into the machine, the machine should just append it to the bookmark table, right?
The first instance of namespace is the table, or in NoSql language, a graph. So we have a semantic agreement among us all, the user gets a local namespace that is persistent and needs no prefix to identify its location. By the way, the machine simply opens a graph context on the table, and the ready set row pointers are set up for call back on precompiled, high speed bind, sql operators. Once the bookmark table is open, this thing is blindingly fast and accurate.
At some point, Json will want us to say, #bookmark, to identify the fact their is no higher namespace reference. But don't need it now, do we. Want to recover a bookmark? Well, bookmark.joe.* is the informal, query, the one I have been using. But internally, that is @joe.*,bookmark as the internals is set up for a binary lambda operation? Right? The missing thing in Json, the lightweight 'Tree Climb' we might say, the thing we do with Doms. Well this machine has that in spades. That is the idea, cruise the big graph.
So, lets set a target, make table names first and foremost a space reserved for the local client and see what happens. Then we market this thing as the personal, Json natural client name space, as an easy to use Json compatible adjunct to the browser. How about that! I can do that in a jiffy.
But wait!!! What abo that informal query? Am I going to war with the quotes? We have to say bookmarks."joe" to differentiate with bookmarks.title; and we can match otherwise using position. Then that leads to bookmarks$url to pick off one field in a bookmark, regardless o0f position? I have little clue about some of this, except to say, whatever the ultimate standard, there will be a Lazy J version of it. In the meantime, I can make things up.
The first instance of namespace is the table, or in NoSql language, a graph. So we have a semantic agreement among us all, the user gets a local namespace that is persistent and needs no prefix to identify its location. By the way, the machine simply opens a graph context on the table, and the ready set row pointers are set up for call back on precompiled, high speed bind, sql operators. Once the bookmark table is open, this thing is blindingly fast and accurate.
At some point, Json will want us to say, #bookmark, to identify the fact their is no higher namespace reference. But don't need it now, do we. Want to recover a bookmark? Well, bookmark.joe.* is the informal, query, the one I have been using. But internally, that is @joe.*,bookmark as the internals is set up for a binary lambda operation? Right? The missing thing in Json, the lightweight 'Tree Climb' we might say, the thing we do with Doms. Well this machine has that in spades. That is the idea, cruise the big graph.
So, lets set a target, make table names first and foremost a space reserved for the local client and see what happens. Then we market this thing as the personal, Json natural client name space, as an easy to use Json compatible adjunct to the browser. How about that! I can do that in a jiffy.
But wait!!! What abo that informal query? Am I going to war with the quotes? We have to say bookmarks."joe" to differentiate with bookmarks.title; and we can match otherwise using position. Then that leads to bookmarks$url to pick off one field in a bookmark, regardless o0f position? I have little clue about some of this, except to say, whatever the ultimate standard, there will be a Lazy J version of it. In the meantime, I can make things up.
Alabama to legalize political corruption
The Alabama House of Representatives is considering two new bills that combined would grant the governor power to create business development tax incentives in the state and then shield those decisions from the court's oversight.If anything thinks this is any else but pure corruption, then that is some fool.
HB 160 allows the governor to initiate a large tax incentive at the suggestion of the Alabama Development Office and the Department of Revenue. Tax Analysts' David Brunori points out the bill "would allow the governor 'at his or her discretion' to let a company keep from 50 to 90 percent (again at the governor's discretion) of the state income tax withheld from workers." Tax Foundation
Who is the corrupt governor? Robert Bentley. He has convinced Alabama voters, he has Jesus on his side.
Alabama voters are complete fools.
I figured out the ATT gift card scam
Uverse users can no longer use unauthorized payment centers, the ATT billing system is broken into two parts. Stanrad POTS supports unauthorized billers, Uverse does not. So the idea was to give everyone a gift card, then everyone has an online payment system. So I guess the new process is walk to the bank, put money on the gift card, then pay the bill online.
The other scenario is to cancel and buy the cable TV version of internet, but make sure they have an unauthorized payment system set up first. I don't keep credit carss nor checks, so I am screwed until three weeks when my gift card comes in. They are likely to turn me off before then.
The CEO of ATT needs to be fired immediately.
The other scenario is to cancel and buy the cable TV version of internet, but make sure they have an unauthorized payment system set up first. I don't keep credit carss nor checks, so I am screwed until three weeks when my gift card comes in. They are likely to turn me off before then.
The CEO of ATT needs to be fired immediately.
Lost patience with ATT
They tell me I canot have my full account number unless I login to my account. I have no online account with ATT and if I had one, I likely have our or five from the trying previous attempts to register. Maybe the best solution is to cancel the account entirely and just get Internet from he Cox cable right above my head.
The lady says that If I wanted to pay my ill I could. Yet I go to three normal stores that accept payments, none of them recognize my uverse account number. They gave me the account number! I call them up and verify the correct account number, they tell me that is only part of the account number, the rest is secret, I have to login to get the rest of it. Why do they tell me this now instead of when they first gave me the account number.
At this very moment I am having an insanity attack trying to find thing on the ATT websitre, the most horrible thing I have seen.
The lady says that If I wanted to pay my ill I could. Yet I go to three normal stores that accept payments, none of them recognize my uverse account number. They gave me the account number! I call them up and verify the correct account number, they tell me that is only part of the account number, the rest is secret, I have to login to get the rest of it. Why do they tell me this now instead of when they first gave me the account number.
At this very moment I am having an insanity attack trying to find thing on the ATT websitre, the most horrible thing I have seen.
Json name spaces, a big topic currently
The issue is how can Json indicate the namespace where symbol definitions reside for any given transaction. he really boils down to finding the proper table to perform look up., the semantics do to go beyond that. Anything beyond that requires humans to agree on some semantics, I doubt we can avoid that.
Hence the reason I hesitate in jumping in, there has been a of of thought on the problems since 2006 and much of the discussion posted, a lot of issues discussed and I am better off reading the current state of the discussion before proceeding. Here is a good overview of naming.
URLs can uniquely identify a look up list, URLs are unique be we don't all have one. If my bot is roaming and want to look something up in its unique table, then it needs its own unique URL. Actually the best bet here would be for clients to obtain a unique hash which they can keep.
In the local case, he client just manages local name space for bookmarks, files, and names and places. Hence, he does not need prefix his url, the default local namespace is used. Maybe work on that?
Hence the reason I hesitate in jumping in, there has been a of of thought on the problems since 2006 and much of the discussion posted, a lot of issues discussed and I am better off reading the current state of the discussion before proceeding. Here is a good overview of naming.
URLs can uniquely identify a look up list, URLs are unique be we don't all have one. If my bot is roaming and want to look something up in its unique table, then it needs its own unique URL. Actually the best bet here would be for clients to obtain a unique hash which they can keep.
In the local case, he client just manages local name space for bookmarks, files, and names and places. Hence, he does not need prefix his url, the default local namespace is used. Maybe work on that?
Victor David Hanson does not have voting rights
In the past 40 years, the United States has intervened to go after autocrats in Afghanistan, Grenada, Haiti, Iraq, Libya, Panama, Somalia, and Serbia. NRO
Do some math my fellow Fresnoite, we do not have Senate vote in California. That makes DC an oligarch and Californians colonies. The dictators are right here, the small state Tea Party socialists taking advantage of your lack of voting rights.
Why do we even pay stock brockers
U.S. stocks erased earlier gains as Federal Reserve Chairman Ben S. Bernanke’s remarks to Congress damped speculation of more quantitative easing to stimulate growth in the world’s largest economy. BloombergThey can't find value so they just take direction from Ben.
IDIOT California Republican
Ventura County could be hit hard if Defense Secretary Leon Panetta's plan for military base closures goes through and the bases at Port Hueneme and Pt. Mugu get hit, but Sen. Tony Strickland (R-Moorpark) is taking steps to avoid that possibility.
What exactly does this bozo want? California pays a premium in taxes for the military bases, they are a losing proposition. Republican socialist, easy to spot they are generally found in government halls looking for goodies regardless of who pays.
Bull pucky on the Tea Party book.
In The Tea Party: Three Principles, constitutional law professor Elizabeth Price Foley takes on the mainstream media's characterization of the American Tea Party movement, asserting that it has been distorted in a way that prevents meaningful political dialogue and may even be dangerous for America's future. Foley sees the Tea Party as a movement of principles over politics. She identifies three "core principles" of American constitutional law that bind the decentralized, wide-ranging movement: limited government, unapologetic U.S. sovereignty, and constitutional originalism. These three principles, Foley explains, both define the Tea Party movement and predict its effect on the American political landscape. Foley explains the three principles' significance to the American founding and constitutional structure. She then connects the principles to current issues as health care reform, illegal immigration, the war on terror, and internationalism.Amazon is selling it
Translation, small states with 8-10 times the voting power of Californian want Big Socialist Defense and make California and Texas pay for it.
What does Glenn Renyolds at Instapundent think? he thinks government begins iand ends in DC, he has no clue what a socialist he really is
ATT the problem
Using the monopoly status of ATT, the CEO sets up worthless profit centers for his buddies, then charges the consumer for the horrendous costs these centers create. Att started he mess by calling me constantly to upgrade to Uverse. They offer it to me at the current price. Since then they have gotten the fucking gift card center involved. Now they want to screw with the accout number, changing the format and the local store where I pay my bill c can't work it out. The payment process center is about to cost ATT another $100 and I sit on the phone asking why the local store payment process wont'e work.
The ATT call center folks gets pissed at the buddy=buddy profit center crap and are just as pissed off as me.
Solution? Scrap the whole company and go to the cable system? Maybe, just knowing that this goes on convinces me he ATT CEO is an idiot, delusional. There is no other explanation.
The ATT call center folks gets pissed at the buddy=buddy profit center crap and are just as pissed off as me.
Solution? Scrap the whole company and go to the cable system? Maybe, just knowing that this goes on convinces me he ATT CEO is an idiot, delusional. There is no other explanation.
Nano technology and water desalinization
This study might have an important impact on water desalinization and filtration methods. Two articles published in Science state that the introduction of graphene membranes and carbon nanolayers will revolutionize water desalinization and filtration processes, as water diffuses rapidly through these materials when their pores are 1nm in diameter. Science DailyWe have seen videos of this process, gravity flow of dirty water through a nano filter cleans it up. This research points out why water behaves so nicely with nano channel at 1nm scale (molecular size). Nano technology is a big deal, a necessary deal as a matter of fact.
High frequency trading is built upon bad math

Check this chart. One would have to be a damned stupid trading bot not to notice the redundancy in this series. Smart bots check the information efficiency of the series, and compute an approximate SNR for the series. Then these smart bots decide, using their programmed values, how much information to they want to reveal given the current SNR of the market. The stock market obeys Shannon Theory use it, Shannon did. We have a name for it, Kelly Betting.
HT Modeled Behavior commenting on a John Cochrane article.
Meth reaches the children of political leaders
Chikhani, who has faced drug charges a number times over the past decade, was in Santa Clara County Superior Court on Tuesday after a California Highway Patrol officer pulled him over on Stevens Creek Boulevard in San Jose in September and allegedly found a bag of methamphetamine in his maroon 2003 Nissan 350Z. He faces four charges: possession of methamphetamine, being under the influence of a controlled substance, possession of drug paraphernalia and resisting arrest for refusing to get out of his car voluntarily. John Lockyer son in lawThe drug has ruing the lives of the kids, so typical. No one tells these kids that meth is especially pernicious. I will tell you, use this drug and you are disabled for life.
Tuesday, February 28, 2012
How is the software going you ask?
In a pause, for the usual reasons, trying to figure out Json's future. Specifically, will Json ever get a lightweight lambda operator, or are we stuck dragging javascript into the picture at every node? Json schema, I think has won its place, but schemas are still just a graphs. I will likely spend some time incorporating schemas, but absent the lambda, all I can do is make yet another Javascript controlled Json server. Once the industry works out a Json bot protocol, adding the code is a no brainer. Adding a lightweight lambda operator makes the bots move. You know, jumping out ahead of the market is a fools errand, I am better off looking at theory.
How do I code a Json schema pattern in C? I go to the php version and do cut and paste, it is a small module. I just adapt the code that does not already exists in my software. What's missing in my software? Namespace indexing, all those reserved words in Json schema have to come from the indexing system. Which is to say, it is not just a bunch of c code, it is a standard Qson graph with its own name space.
How do I code a Json schema pattern in C? I go to the php version and do cut and paste, it is a small module. I just adapt the code that does not already exists in my software. What's missing in my software? Namespace indexing, all those reserved words in Json schema have to come from the indexing system. Which is to say, it is not just a bunch of c code, it is a standard Qson graph with its own name space.
Big Government Republicans busted
This us how much debt Republicans plan relative to Obama, from the center for Responsible Federal Government.

These is no debate here, Republicans are the party of borrow and spend. They do intend to bankrupt DC with big Republican Spending. HT Delong and Krugman
Case Schiller metropolitan housing prices
Poated at WSJ. Once again, Washington DC holds the lead, though it shares it with Phoenix for the year. But overall, Washington DC housing prices are way ahead of any other metropolitan district. As of Dec 2011, DC housing has help up at 179, it partner NY at 163. All other markets ave5rage about 120.
So, economists who have plans for DC to fix the housing market, should explain this. I mean, blame the recession on housing wealth loss, then encourage to government to send housing money6 to the DC housing market? Kind of stupid, or perhaps a bi dishonest.
So, economists who have plans for DC to fix the housing market, should explain this. I mean, blame the recession on housing wealth loss, then encourage to government to send housing money6 to the DC housing market? Kind of stupid, or perhaps a bi dishonest.
The ATT gift card concept
The bozos at their marketing department came up with some bozo idea. They would issue a gift card to cover the cost of them upgrading your equipment. They wanted the upgrade not me. They had this idea of issuing a gift card, and the customer could use the gift card to pay for ATT equipment upgrades. Pretty damned stupid considering they could just cancel the charge for a few keystrokes.
They have an entire department and information service devoted to sending out and accepting ATT gift cards. The only purpose of whicyh is to cover ATT services! This sounds like one of those sweetheart deals where an ATT exec got his buddy a great business contract for credit cards. Now this little stunt means that when ever ATT issues a gift card to cover their equipment expense of $100, they will spend $200 explaining to rational people why they just cannot cancel the equipment charge. Somebody over at ATT is out of their mind.
They have an entire department and information service devoted to sending out and accepting ATT gift cards. The only purpose of whicyh is to cover ATT services! This sounds like one of those sweetheart deals where an ATT exec got his buddy a great business contract for credit cards. Now this little stunt means that when ever ATT issues a gift card to cover their equipment expense of $100, they will spend $200 explaining to rational people why they just cannot cancel the equipment charge. Somebody over at ATT is out of their mind.
More denial of energy shortages from John Whitehead

His claim is that consumers only lost $150/month on the average, and were not bothered. But one producer delivers products to 10 consumers, the ten consumers have $1500 less per month, the producer energy costs drive down his margin, he exits the business. Again, look at the key indicator CPI/PPI and watch which one turns first, PPI, producers dropped out, not consumers. This was a supply side recession caused by energy shortages.
Santorum is correct about this. Housing followed inflation, inflation followed the energy shortages, producers collapsed, Lehman failed and we are still stuck with energy shortages.
Let's try out some schema with typeface explosion
First, the definition of schema is that namespace of system reserved words. When you cut through the esoteric, this is the real meaning. So lets assume out engine knows schema, at least the @ variant of Lazy J. What does this do:
@Schema:,@SearchGraph,DataGraph
I presume it emits the collected results formatted according to the schema graph. Schema:Schema_Definition is not the @ variant creates a Qson graph, it has no understanding of schema. But how do we define a new graph having schema? NewGraph@Schema,SystemCreate ? Do I have a reserved term just for this engine? Javascript uses var as in: Schema variable_name;
I don't have these answers, but I will soon!
@Schema:,@SearchGraph,DataGraph
I presume it emits the collected results formatted according to the schema graph. Schema:Schema_Definition is not the @ variant creates a Qson graph, it has no understanding of schema. But how do we define a new graph having schema? NewGraph@Schema,SystemCreate ? Do I have a reserved term just for this engine? Javascript uses var as in: Schema variable_name;
I don't have these answers, but I will soon!
Json schema
Already defined, here is an example from the web:
Good enough, let me think on it. Here is Kendo, one of my competitors. Likely my closest competitor. If we all agreed on the reserved words, schema, model, required, fields; then we would have a NoSql Sql! Google has a project on this schema thing, I will look at it. And there is a RFC standard:
They are making the equivalent of XSLT that XML uses to describe schema.If it sticks we are going to get reserved words, but I am in, I like it.
The goal is to ave graph creation, modification, indexing and deletion all happen at the graph layer without invoking Javascript. We want Json just a bit more active, but not a full language, we want the bots to move pretty fast.
schema: { data: 'GetRolesResult.Roles',
model: { id: "RowKey",
fields: {
RowKey: {},
name: { validation: { required: true} },
read_: {}
} }Good enough, let me think on it. Here is Kendo, one of my competitors. Likely my closest competitor. If we all agreed on the reserved words, schema, model, required, fields; then we would have a NoSql Sql! Google has a project on this schema thing, I will look at it. And there is a RFC standard:
They are making the equivalent of XSLT that XML uses to describe schema.If it sticks we are going to get reserved words, but I am in, I like it.
The goal is to ave graph creation, modification, indexing and deletion all happen at the graph layer without invoking Javascript. We want Json just a bit more active, but not a full language, we want the bots to move pretty fast.
Nt quite Doug Mataconis
Watch Doug Mataconis of Outside the Beltway bury himself:

Doug says we have cause and effect wrong. What caused the gas price hike in 2005, and how did the financial shenanigans caused the price spike in spike 2008? Why is it that since 2001 the real and nominal price of oil track so closely?
Doug cites another post by Zeke Miller::
If we can recall, the Financial Crisis committee was only allowed to investigate finacial issue, they were bot charge wit looking at energy shortages in 2005-2008.
The problem here is bad math. Doug should know that when the real price of a good tracks the nominal price to a correlation coefficient of .9 over a ten year period, then we have a shortage, and we have suffered severe energy shortages since 2000.. There is no way around this math, if money means anything.
Denial:
There as been a huge denial of the problem, though I do not know why. We talk about Peak Oil endlessly, then when the crash comes, we deny it happened!
Like I said, it’s likely that increasing energy prices at the start of the recession made an already bad situation worse, but the cause-and-effect argument that Santorum is making here makes no sense whatsoever. Outside the BeltwayGreat, he buries digs in on his position
2) On content, this seems like a pretty clear case of getting the direction wrong. Lehman fails in September 2008 and the economy collapses. That leads gasoline prices to plunge precipitously (check out the price series at http://gasbuddy.com/gb_retail_price_chart.aspx and click on the 5 year or 4 year graph) according to all analysts at the time because people understand output will be falling, not the other way around.
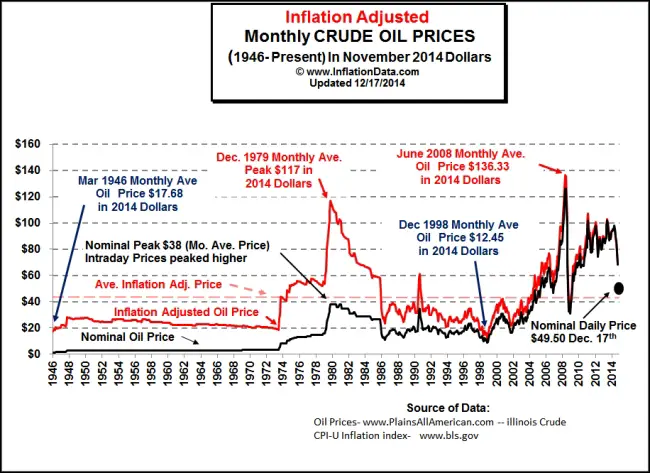
Doug says we have cause and effect wrong. What caused the gas price hike in 2005, and how did the financial shenanigans caused the price spike in spike 2008? Why is it that since 2001 the real and nominal price of oil track so closely?
Doug cites another post by Zeke Miller::
Santorum’s comments appear to stretch the limits of credulity. The words “gas,” “gasoline,” and “energy” to not appear in the conclusions of the congressionally-appointed Financial Crisis Inquiry Commission,tasked with exploring the root causes of the 2008 recession and financialcrisis.
If we can recall, the Financial Crisis committee was only allowed to investigate finacial issue, they were bot charge wit looking at energy shortages in 2005-2008.
The problem here is bad math. Doug should know that when the real price of a good tracks the nominal price to a correlation coefficient of .9 over a ten year period, then we have a shortage, and we have suffered severe energy shortages since 2000.. There is no way around this math, if money means anything.
Denial:
There as been a huge denial of the problem, though I do not know why. We talk about Peak Oil endlessly, then when the crash comes, we deny it happened!
Cal State Pay Scandal proves need for on line academics
Under Herbert Carter’s tenure, the Cal State University system has approved “hefty salary increases” for its top executives “without public input” during the state’s “most dire funding predicament.”
Those aren’t quotes from recent news stories about the Cal State’s administrative pay scandal. CalWatchdog has rummaged through the archives and unearthed the news stories from the Cal State’s first executive compensation scandal. Cal Wath
Here at Imagisoft we will monitor an certify your completion o the MIT undergraduate program, on line. And you will not be required to pay some bureaucrat hundreds of thousands.
Nancy Pelosi energy expert
“Independent reports confirm that speculators are driving up the cost of oil, hurting consumers and potentially damaging the economic recovery. Wall Street profiteering, not oil shortages, is the cause of the price spike. In fact, U.S. oil production is at its highest level since 2003, and millions of acres have been cleared for additional development. Zero HedgeThat representative was elected by the SF meth addicted population, all they know is conspiracy.
Monday, February 27, 2012
A way out of the naming issue
Let the user work from his own and a suggested set finite set of names. He can construct his personal world with a name list, bookmarks, email addresses, a mails, gists and notes, working documents, etc etc. As many names as the user wants,files; they become unique indices into his information storage. Give the client a tool to manage his name space, then from then on, it is dra and drop, tag, any documents can be pointed to from one of the names in his name space. He can nest his name space, do anything with the name space that can be represented in a Json string.
Fro the engine's point of view, is is just another Qson table, but we create the indexed attribute on this table, we know wight away on look up that this is client name space. Any element named with a naming element will be tagged as a member of that set of elements. Then using the client name space, the power of Sqlite3 becomes a natural Json breeze.
On start of a run, the client's name space (or part of it) into the qsort/bsearh symbol table in ram. Access to the subgraph elements of a tagged graph, not a problem when we have rowids and table names That is what I can work on, and let the Json/browser technology proceed on its own.
What would a bookmark list look like in Lazy J?
Bookmark.{title1.url1.icon1.ip1,table2.url2.icon2.ip2, ..,}
So when running this table, the default here is that bookmark is a valid symbol, the engine looks it up. But Bookmark:{NewTitle.UrlNew.IconNew.IP} means to add this to the bookmark subgraph.
So the engine looks up the first item in an expression and is directed from there, but the engine executes a subgraph append if the object is Colonized? I am getting close here, close to something that might work as a tryout.
Fro the engine's point of view, is is just another Qson table, but we create the indexed attribute on this table, we know wight away on look up that this is client name space. Any element named with a naming element will be tagged as a member of that set of elements. Then using the client name space, the power of Sqlite3 becomes a natural Json breeze.
On start of a run, the client's name space (or part of it) into the qsort/bsearh symbol table in ram. Access to the subgraph elements of a tagged graph, not a problem when we have rowids and table names That is what I can work on, and let the Json/browser technology proceed on its own.
What would a bookmark list look like in Lazy J?
Bookmark.{title1.url1.icon1.ip1,table2.url2.icon2.ip2, ..,}
So when running this table, the default here is that bookmark is a valid symbol, the engine looks it up. But Bookmark:{NewTitle.UrlNew.IconNew.IP} means to add this to the bookmark subgraph.
So the engine looks up the first item in an expression and is directed from there, but the engine executes a subgraph append if the object is Colonized? I am getting close here, close to something that might work as a tryout.
Now what with the Json engine
Well, the main thing we want for for clients to drop items onto their browser widgets, tag items, retrieve them all using the client's own names space. So it would seem my value added would be improving he name space making Sqlite3 index system available to the client. The browse side is already populated with tool and widgets, it already talks Json, so this engine code is building into that existing market. The browser folks have great libraries, a multitude of ways to render Json. Let them do their job.
Nut names space for the client, that is where the advantage, but naming has to be naturally to the client and still fit into the Json framework. that is the big Hmm... Imgisoft is on the case. I have been browsing the forums and user groups, what they are using, getting idea. Like this one guy has a few lines of c code that works with Sqlite, giving sqlite3 the natural ability to store IP4 and IP6 addresses in the same record format. But we are not even that far, we still have to figure out naming space when the user is dealing only with local data.
It is the totality of it, the desire to get a Json naming custom, or reference point for applications. I need a target, a vision of how a client might just want to deal with a gaggle of bookmarks, can he just drag them onto the engine and have it sort things out? How? Hmm..
Think about dragging a bunch of bookmarks over to the engine. It can do that because browsers can export Json strings of bookmarks. The engine can store them, keep the serialization format, and index on any one of the bookmarks, on any column. But is there a naming standard? Do clients all agree that the name bookmarks means something. And is that always going to be the cosument name for bookmarks? The industry has standards here, but the connection is never created until the standard is natural to the client, this is an information interface.
Nut names space for the client, that is where the advantage, but naming has to be naturally to the client and still fit into the Json framework. that is the big Hmm... Imgisoft is on the case. I have been browsing the forums and user groups, what they are using, getting idea. Like this one guy has a few lines of c code that works with Sqlite, giving sqlite3 the natural ability to store IP4 and IP6 addresses in the same record format. But we are not even that far, we still have to figure out naming space when the user is dealing only with local data.
It is the totality of it, the desire to get a Json naming custom, or reference point for applications. I need a target, a vision of how a client might just want to deal with a gaggle of bookmarks, can he just drag them onto the engine and have it sort things out? How? Hmm..
Think about dragging a bunch of bookmarks over to the engine. It can do that because browsers can export Json strings of bookmarks. The engine can store them, keep the serialization format, and index on any one of the bookmarks, on any column. But is there a naming standard? Do clients all agree that the name bookmarks means something. And is that always going to be the cosument name for bookmarks? The industry has standards here, but the connection is never created until the standard is natural to the client, this is an information interface.
Perfect Json out from Sqlite3
Going in from the browser query window:
{$RunTable@SystemExec,select * from test;}
Coming out, a Json encoded square table:
{0.1.Row0},{1.2.Row3},{0.1.Row5},{2.3.Row4}
The intermediate form is a Qson table in Sqlite3. Any table in sqlite is presentable as an html table, and can be loaded into an Html widget.
{$RunTable@SystemExec,select * from test;}
Coming out, a Json encoded square table:
{0.1.Row0},{1.2.Row3},{0.1.Row5},{2.3.Row4}
The intermediate form is a Qson table in Sqlite3. Any table in sqlite is presentable as an html table, and can be loaded into an Html widget.
Sunday, February 26, 2012
Full featured
I have a Json search script in the browser window and Json delivered out, Sql B Tree power under the hood. It uses SystemCalls, so it goes through the symbol path. And it also is the first rudimentary binary operation if the system call is considered a graph. A bit buggy, but operational on all paths and stable for normal testing. Not something yet for beta, but a bit of testing and it and be used. This is the new model for networking. Right now anyone with my IP could read and write Json tables to my Sqlie3 base.
Today, I could use the system to have a service autonomously download my news to a secure, high speed data base. How is it going to get from Sqlite3 to my OS? It can't, Sqlite3 is part of the public net, but isolated from my internals. It is like the browser, in a protected playground. I should publish my IP address, but I would rather have my IP address managed by a service provider.
So great, the new era is here. Another few days as this thing gets rock solid, I will find Json widgets that can display tables and so on. We are going to need informal IP address exchange protocols, so you can update my table and I tours. We need some encryption and security key software. Fun,fun,fun. This thing will be a must have for all the info geeks.
Today, I could use the system to have a service autonomously download my news to a secure, high speed data base. How is it going to get from Sqlite3 to my OS? It can't, Sqlite3 is part of the public net, but isolated from my internals. It is like the browser, in a protected playground. I should publish my IP address, but I would rather have my IP address managed by a service provider.
So great, the new era is here. Another few days as this thing gets rock solid, I will find Json widgets that can display tables and so on. We are going to need informal IP address exchange protocols, so you can update my table and I tours. We need some encryption and security key software. Fun,fun,fun. This thing will be a must have for all the info geeks.
What does Shannon say abuot the expansion of the unverse?
Consider the theory of maximum entropy. The universe cannot track all intermediate states, it will be optimized in one state having increasing inventories and reduced rank, or another state of increased rank and decreasing inventory. The signal to noise ratio of nature would be fixed, it hops between two bandwidth states, high/low. The high bandwidth state is the decreasing inventory state. The SNR related to Plank's constant. Nature flips between encoding solutions. The unkown here, is can Nature move more than one rank up or down?
God is the great aggregator
Richard Dawkins, the atheist intellectual can't say anything certain about god. I can.
God is the process of finding unattended aggregates and packaging them for minimum step delivery. That process underlies evolution, particle physics, information flow, education, everything, it is the fundamental process. In other words, we can say the god process is one of counting everything to a constant certainty with the minimum number of bits.
The god we human's love to love is seen in the process of self-discovery, our entire brain tracks the self discoveries of nature. We literally have counters that count out the discovered aggregates throughout the day, we count out moves through the grocery stand, around the corer, we count the pattern of entering and leaving cars, we have dithering counters that flutter our eyes during focus. Everything we think and do is a counting out of discovered things. Every movement we make is an actuated counting pattern.
God is the process of finding unattended aggregates and packaging them for minimum step delivery. That process underlies evolution, particle physics, information flow, education, everything, it is the fundamental process. In other words, we can say the god process is one of counting everything to a constant certainty with the minimum number of bits.
The god we human's love to love is seen in the process of self-discovery, our entire brain tracks the self discoveries of nature. We literally have counters that count out the discovered aggregates throughout the day, we count out moves through the grocery stand, around the corer, we count the pattern of entering and leaving cars, we have dithering counters that flutter our eyes during focus. Everything we think and do is a counting out of discovered things. Every movement we make is an actuated counting pattern.
Saturday, February 25, 2012
Dealing with Json output
Consider the general form again: Gout@G1,G2
Both G1 and G2 are directed graphs without loops, and the @ operator is a single atomic operation, with grammar rules that guarantee a complete exploration of G1 an G2. That means any emissions from the convolution come out in nested order, and can be streamed as multi-part Json documents. All the code is there to do this task, the emission, even from square tables, look like sequence of |link|rowcount|key value. There is a few days work, but then we get intelligently structure Json results from a query by example between two Jsons. Otherwise the compete system if stable, at moderate transaction rates. I have a lot of defined limits, still. This thing is going to be a personal Watson.
Both G1 and G2 are directed graphs without loops, and the @ operator is a single atomic operation, with grammar rules that guarantee a complete exploration of G1 an G2. That means any emissions from the convolution come out in nested order, and can be streamed as multi-part Json documents. All the code is there to do this task, the emission, even from square tables, look like sequence of |link|rowcount|key value. There is a few days work, but then we get intelligently structure Json results from a query by example between two Jsons. Otherwise the compete system if stable, at moderate transaction rates. I have a lot of defined limits, still. This thing is going to be a personal Watson.
From the browser to the table to the console to the browser
I can use the console or jcon remote and add tables, using either keyboard or json files or load Json from the net. Then I can read them from the browser, as plain text, at least. That means the system path is working at all directions, including installs. I can do an sql script to read, and simple Json to write. Now to merge the two.
Sorry about burning all those crayons
Foreigners are upset about burning crayons and crayola, missing colors an all that. I have burnt my share of crayon, big deal when you are a kid. You can just melt them with candle wax. But, anyway, sorry for upsetting all the crayon lovers.


Crayon lovers in anguish
Just naming tables in the current system
Opening the browser and typing in {some text,and more,"quote me on that"} makes a great table, but absent some info about what to do with it, the table is erased the next tie you hit submit. Do we start off right away with named tables?
TableName:{Some stuff} I think so, an that has to be the next step, right? Otherwise table keep going away. Separating different users? Hmmm.. , oh yea, the default name was the return URL, no, Hmm... And no, we cannot use : for table naming, that is for subgraph naming, and subgraphs may be a partition of a table.
See, I am a bit lost. That is why I saved the @, because that gets me a specified output, and two inputs, the client is forced to use graphs as expressions, and the enclosed naming spaces should point to enclosed subgraphs naturally.
TableName:{Some stuff} I think so, an that has to be the next step, right? Otherwise table keep going away. Separating different users? Hmmm.. , oh yea, the default name was the return URL, no, Hmm... And no, we cannot use : for table naming, that is for subgraph naming, and subgraphs may be a partition of a table.
See, I am a bit lost. That is why I saved the @, because that gets me a specified output, and two inputs, the client is forced to use graphs as expressions, and the enclosed naming spaces should point to enclosed subgraphs naturally.
A decision point on Lazy J
I have a conflict between human convenience and strict computer rules regarding Lazy J. Human convenience should prevail. Consider keywords typed in the human. He has already decoded tem, they are immediates, not symbols. {Key1,Key2} means find key1 or Key2 the exact text, as opposed to $Key1 or $Key2. It fouls me up when the default typing is keyword instead of symbol, too many dollar signs. But I can live with it, as a developer, if it lets the client type bare keywords with comfort. I still like the idea that a quote signifies a bags of keyword, that would be a great compromise.
This is all looming on the horizon, now that we have a complete system with an incomplete search and construct language. Right now the nest thing on my todo list is he Ugly Handler, what is the grammar when two Qsons are run through the execution machine, as opposed to just moving around. I have to work the language anyway to get access to my System calls. But that means I have to dollar up all ny system call syntax. We could say that the symbol table reports back that this must be immediate by having no entry, but the machine cannot rely on that when it runs autonomously. This si where the NoSql crowd can jeer, because I cannto do anything in defaul grammar that is not natural to sqlite3. When the client give the machine G1{Myname,mycar,myaddres}, then Sqlite can run a match, even nested graph matching right off of that in table Qson form, but it cannot do look ups. I could write a call back, but really, let the client type in bare key words as default. Since we know when a symbol is created or redefined, the : tells us, we are better to silently flag the symbols, and leave the unflagged as default bare key word.
Pushing this thing into territory I am still learning about.
This is all looming on the horizon, now that we have a complete system with an incomplete search and construct language. Right now the nest thing on my todo list is he Ugly Handler, what is the grammar when two Qsons are run through the execution machine, as opposed to just moving around. I have to work the language anyway to get access to my System calls. But that means I have to dollar up all ny system call syntax. We could say that the symbol table reports back that this must be immediate by having no entry, but the machine cannot rely on that when it runs autonomously. This si where the NoSql crowd can jeer, because I cannto do anything in defaul grammar that is not natural to sqlite3. When the client give the machine G1{Myname,mycar,myaddres}, then Sqlite can run a match, even nested graph matching right off of that in table Qson form, but it cannot do look ups. I could write a call back, but really, let the client type in bare key words as default. Since we know when a symbol is created or redefined, the : tells us, we are better to silently flag the symbols, and leave the unflagged as default bare key word.
Pushing this thing into territory I am still learning about.
Target beta
I am moving on from alpha, I have banged the thing. I have now installed the complete same origin server with simple file server capability, built in. I use the same origin directory for moving files into tables, from the console command line, as well as delivering files to remote browser. This capability is the minimum for merging same origin web policy and local file management. At this point, when I run the engine, any browser in the word can point at my IP and see my Sqlite3 tables. Their browser loads up index.html which has the simple query input and output windows. But it is not user proof yet, easy to crash with bad syntax. The only function it knows is make a Qson from your Json, and return Json from a Qson table, and the latter not fully debugged from the browser.
These are the new magincs:
#define JSON_TYPE "application/json"
#define QSON_TYPE "application/qson"
#define MULTI_TYPE "multipart/form-data"
If you send multi-part, send only one part, send one part of anonymous bytes with balanced brackets. Bson is out for now. Json from a browser textarea is standard.
These are the new magincs:
#define JSON_TYPE "application/json"
#define QSON_TYPE "application/qson"
#define MULTI_TYPE "multipart/form-data"
If you send multi-part, send only one part, send one part of anonymous bytes with balanced brackets. Bson is out for now. Json from a browser textarea is standard.
I fear multi-part data
Html multi-part data is the extreme in typeface explosion, blow your socks off, never look at it directly.
What I want is the \r\n\r\n magic. When the machine sees that code, then it gets to have the remainder as plain bytes. I want the following function:
DoubleReturnNewLineCodeHttpGetRequest();
It has two methods, get_the_stuff and put the stuff.
What I want is the \r\n\r\n magic. When the machine sees that code, then it gets to have the remainder as plain bytes. I want the following function:
DoubleReturnNewLineCodeHttpGetRequest();
It has two methods, get_the_stuff and put the stuff.
Friday, February 24, 2012
Full duplex path to the browser
I worked around the so called same origin policy, the policy that says once a page loads, it can only get additional info from the original url of the top level document. So one makes the local server dish up the starting page, and any other data responses will be accepted by the browser. My starting page comes up with a Lazy J input text area and an engine out test area. You send it the one an it fills the other. This is the latest method to make your home computer a server. Fossil uses it, so the CaYa, and a few others. But it will become the norm.
So my machine is wired to the max, and debugging new modes of operation will be simpler and simpler as users get more javascript. For example, I an make a remote debugger, works through the browser and lets you debug special sql sequences.
So my machine is wired to the max, and debugging new modes of operation will be simpler and simpler as users get more javascript. For example, I an make a remote debugger, works through the browser and lets you debug special sql sequences.
Thursday, February 23, 2012
Breakthrough
I can use cutnpaste into my browser, pasting Json segments and they are entered into the sqlite table. Repeatedly, test with all sorts of white space every where. So a simple html edit window now is as fast as any Giggle search. Even at this level, the ability to cutnpaste bookmarks, text snippets and quotes into premanent, searchable, indexed, named Json snippets, Send them to all you friends. create tables on the fly, just for temorary storage, then cut them down later with key word extraction and other ontology tools. Replace csv files, all that, new Json consoles. Lazy J will spread like wild fire.
What's the point of IP V6 if our browser can't listen?
Just saying, there is no cost in listening for incoming tcp connections.
I am going to call my new language the @ variant
It has two rules. @ is valid variable from a binary operation on two valid variables. No, wait, that's one rule! My user's manual will be 2,000 pages long, 1,999 of them let for reader exercises.
Congratulate the heros
Who made it possible for a guy in Fresno to compete with huge software companies? let me list them, in no particular order. The c language, open software, especially gethub, browser technology and html, doxygen, Sqlite3, Json marketing in general, fiddler, sockets, and windows ability to be fairly compatible, posix, e mail lists, I read them for idea all the time, blogging technology, cutnpaste, Visual Studios, Cygwin was there for the moment I needed it. The list goes on and on, Actual time on the project? Eight months or so, fiddling for a year before that.
I have the best solution, I win.
I have the best solution, I win.
My browser talks to the machine!!
I managed the http thing, it is not my first time but each time I try to forget. Anyway, I can at least point my browser at the engine and it responds hello. So in Javascript, I can at least et at it through the anchor (link) syntax). I can't get javascript send to work the way I want, but this is OK for now.
I have it working through an html form, using get and now post. So I created the LazyJ http protocol, make a form, submit to local host as a post with the name LazyJ. The engine will find the LazY text and run it through.
The trick:
I triggger this clikc with:
<textarea id = "input" rows="2" cols="20">
Some input
</textarea>
<a href="" onClick=http_io()>Link</a>
In my test.html file. I put test.html and the g engine code in the same directory. The transfer is plain, undoctored bytes from the text area, exactly what I want. And the header code is still just a few lines of key word search then go on to the content. The system is compatible with the console, so the same code still works. I will upload my little test.html. This will speed things up enormously.
But what is the draw back here?
The machine does not know client server,. It knows that it received a self directed Json graph, and it runs it through the machine. If the Json was trying for client server, then Json is lost. That's ok for the lab and alpha, launch and forget. So I worry that later.
I have it working through an html form, using get and now post. So I created the LazyJ http protocol, make a form, submit to local host as a post with the name LazyJ. The engine will find the LazY text and run it through.
The trick:
function http_io()
{
obj = new XMLHttpRequest();
obj.onreadystatechange = function() {
alert('on change ' + obj.status + obj.getAllResponseHeaders());
if (obj.readyState==4) {
if (obj.status!=404) {
alert(obj.responseText);
} else {
alert("Whoops");
}
}
}
alert('new ' + obj.readyState);
obj.open("POST", "http://localhost:8000", true);
alert('open ' + obj.readyState);
obj.setRequestHeader( "Content-Type", "multipart/form-data");
obj.send( document.getElementById("input").value); //text/plain;charset=UTF-8;charset=UTF-8
//obj.send();
alert("sent " + obj.readyState);
}
I triggger this clikc with:
<textarea id = "input" rows="2" cols="20">
Some input
</textarea>
<a href="" onClick=http_io()>Link</a>
In my test.html file. I put test.html and the g engine code in the same directory. The transfer is plain, undoctored bytes from the text area, exactly what I want. And the header code is still just a few lines of key word search then go on to the content. The system is compatible with the console, so the same code still works. I will upload my little test.html. This will speed things up enormously.
But what is the draw back here?
The machine does not know client server,. It knows that it received a self directed Json graph, and it runs it through the machine. If the Json was trying for client server, then Json is lost. That's ok for the lab and alpha, launch and forget. So I worry that later.
Http headers is a worn out technology
The new model is peer to peer, everyone has their own server on their computer. The browsers still act like the old technology client server, they send tons of useless header information. They tell me I cannot turn this off, so your local machine will plow through the useless headers.
So, I have no code yet to plow through headers, and my 10 line magic header wont't work with browsers. My browser tries, I can read all of its information in the engine. They tell me to look for, Content-Type:application/json, white space removed I presume. Then when I find that, I cannot rely on byte count from the browser if it is streaming Json. I have to count brackets, the way I do it at the console.
But I found a program, fiddler, I can construct ad hoc http headers and test them. The machine works, just needs to plow a bit. I think its important to get this connect to the browser.
The strategy here has got to be a reliable Json send and receive from the browser, I move that up in priority.
So I fixed it using strstr, the wonderful little string routine. It finds my magic header and ignores the others: strstr(header,"Content-Type"application/json"); Since I can't rely n content length, I just count brackets and collect.
So, I have no code yet to plow through headers, and my 10 line magic header wont't work with browsers. My browser tries, I can read all of its information in the engine. They tell me to look for, Content-Type:application/json, white space removed I presume. Then when I find that, I cannot rely on byte count from the browser if it is streaming Json. I have to count brackets, the way I do it at the console.
But I found a program, fiddler, I can construct ad hoc http headers and test them. The machine works, just needs to plow a bit. I think its important to get this connect to the browser.
The strategy here has got to be a reliable Json send and receive from the browser, I move that up in priority.
So I fixed it using strstr, the wonderful little string routine. It finds my magic header and ignores the others: strstr(header,"Content-Type"application/json"); Since I can't rely n content length, I just count brackets and collect.
Wednesday, February 22, 2012
Let's keep going on this
In my last post, my example of a nested index look like:
{a0.{b2,b3},a1.{b3,b5.{c1,c2}}}
That is serialized Json, and works well in the engine, frankly. The thing is traversing that well formed descending graph without loops, is nLogN, where N is the graph rank, and we assume constant look up at each table. But the tables are row indexed, the code knows exactly where we are hopping to and Sqlite3 gets what the code knows. Over one table, we might have nested a total of 20,000 entries, each entry having 3 triples of object. But they are all integer arithmetic locations. Generating the nested tables is a snap with Qson rewrite grammar, tou know we always get a Gout in a @G1,G2. lot of optimization solutions and differentiation solutions to make value here.
{a0.{b2,b3},a1.{b3,b5.{c1,c2}}}
That is serialized Json, and works well in the engine, frankly. The thing is traversing that well formed descending graph without loops, is nLogN, where N is the graph rank, and we assume constant look up at each table. But the tables are row indexed, the code knows exactly where we are hopping to and Sqlite3 gets what the code knows. Over one table, we might have nested a total of 20,000 entries, each entry having 3 triples of object. But they are all integer arithmetic locations. Generating the nested tables is a snap with Qson rewrite grammar, tou know we always get a Gout in a @G1,G2. lot of optimization solutions and differentiation solutions to make value here.
More on the indexing problem
More stuff I need to unpatent.
A nested index look up is a graph onvolution. Consider:
G1 = {a1,b2}
G2 = {a0.{b0,b2,b3},a1.{b1,b2}}
then @G1,G2 gives me the final conclusion.
So the grammar in the Ugly handler can treat this like any other convolution. Except for one thing. This convolution is all set up except for supplying G1, ready to run with chained operators. Second, G2 is prepared, the key values indexed by Sqlite3, isn't that nice!! The grammar engine has the ready set, it can pop in one set in place of another. The ready set has all the binding variables and call back variables ready to go. So a look up is, pop in the prepared ready set, point to G1, and run the table. Since table jumps are implicit in the Q operations, the thing will naturally nest through Qson standard, or even square table if set up.
So I make the Qson standard, default math_step operation work and I get nested indexing or free. I really have to make sure this is unpatentable, prior art. Nested indexing has been around, the only thing unique is stepping, but bytecode has that covered. Anything peculiar to sqlite3 is, well, who else is doing it? So I think we are clean. First thing to do after alpha testing complete.
A nested index look up is a graph onvolution. Consider:
G1 = {a1,b2}
G2 = {a0.{b0,b2,b3},a1.{b1,b2}}
then @G1,G2 gives me the final conclusion.
So the grammar in the Ugly handler can treat this like any other convolution. Except for one thing. This convolution is all set up except for supplying G1, ready to run with chained operators. Second, G2 is prepared, the key values indexed by Sqlite3, isn't that nice!! The grammar engine has the ready set, it can pop in one set in place of another. The ready set has all the binding variables and call back variables ready to go. So a look up is, pop in the prepared ready set, point to G1, and run the table. Since table jumps are implicit in the Q operations, the thing will naturally nest through Qson standard, or even square table if set up.
So I make the Qson standard, default math_step operation work and I get nested indexing or free. I really have to make sure this is unpatentable, prior art. Nested indexing has been around, the only thing unique is stepping, but bytecode has that covered. Anything peculiar to sqlite3 is, well, who else is doing it? So I think we are clean. First thing to do after alpha testing complete.
Indexing with the stepping API
The main loop, written in fake software. Some discussion on step_match_fetch follows.
But these are precompiled with chained operators for each of the nested indexed tables. Hence, Sqlite3 can do this way fast enough for data base ops. This will be a snap, but I need install going just dandy (I think they are).
opid = start; // get the operator for the highest level index table repeat // nest through the tables until a solution step_match_fetch(row) // step the machine with the current opid and grab the match if(row.type = index_table) opid = row.data else terminate.OK, step_match_fetch runs through an entire table, and we are really stepping through tables., in thei case sqlite3. We are stepping through tables here, swapping one table for another by chaining their prepared atch operators. The match operators are something like: select * from table where table.key = self.key limit 1; I hereby unpatent the concept.
But these are precompiled with chained operators for each of the nested indexed tables. Hence, Sqlite3 can do this way fast enough for data base ops. This will be a snap, but I need install going just dandy (I think they are).
Javascript naming style
It goes like this: name().occupation(), or they allow structures, name.address. But everything is a variable, everything is looked up and nested. Look up name, and it gives you methods on occupation. We can do the same thing with web bots, only it is more restricted. The entire stepping API is more restrictive then a general Javascript interpreter. But the machine still does nested indexing. Finding an index is step_fetch from the current symbol table. If the result refers to another table, then switch tables and repeat. The machine on start will prepare operators for the known indexing tables, then every index is a simple execution and the results returned. What does an indexing table look like? Dunno, but I am planning to make a square and will likely peruse some other software, like see how Fossil uses indexing tables in sqlite3.
I still worry about when it should do look ups and when not to. There is at least one hidden over loader that tells the machine the current key is immediate. Dunno how and when it is activated from the Json syntax, but I can wing it. But all the indexing tablse will look alike, at least the first few colunms. (The machine can work square tables as variable sized). Probably one of the things I do before too long is implement a nested indexing system. Look around for a B-Tree style, but simple, name space framework, or go for maximum simplicity myself.
Then there are the local look ups, it would be ice to have hidden overloads that identify immediate key, local symbol, or indexed symbol, and a way for Lazy J to pick up on the grammar for that. Hmm... I smell a battle with Quotation marks coming up.
Here at Imagisoft, punctuation marks are a precious commodity, we hat to see them wasted on bland text. But I am thinking of conceding the battle, move on with the show. So, let us say the double quotes means this immediate key value. Now I have a shot, without introducing anything else. If it isn't quoted, if it isn't local, then run the indexer to a conclusion. There, a rule of G grammar, which I will promptly forget.
That means the quotation mark become a standard ugly to the machine, hidden in the link value will be the quotation mark indicator which will stop table look up. It also means I can reproduce the quote marks for Json readers.
I still worry about when it should do look ups and when not to. There is at least one hidden over loader that tells the machine the current key is immediate. Dunno how and when it is activated from the Json syntax, but I can wing it. But all the indexing tablse will look alike, at least the first few colunms. (The machine can work square tables as variable sized). Probably one of the things I do before too long is implement a nested indexing system. Look around for a B-Tree style, but simple, name space framework, or go for maximum simplicity myself.
Then there are the local look ups, it would be ice to have hidden overloads that identify immediate key, local symbol, or indexed symbol, and a way for Lazy J to pick up on the grammar for that. Hmm... I smell a battle with Quotation marks coming up.
Here at Imagisoft, punctuation marks are a precious commodity, we hat to see them wasted on bland text. But I am thinking of conceding the battle, move on with the show. So, let us say the double quotes means this immediate key value. Now I have a shot, without introducing anything else. If it isn't quoted, if it isn't local, then run the indexer to a conclusion. There, a rule of G grammar, which I will promptly forget.
That means the quotation mark become a standard ugly to the machine, hidden in the link value will be the quotation mark indicator which will stop table look up. It also means I can reproduce the quote marks for Json readers.
Making and loading square tables with Lazy J, best approach
I always say, the fastest path is best. The machine has the IO_struct thing, it knows about square. I have already define machine_get_row and machine_get_colinfo. Sqlite3 will make a square for us, but how to we specify in Lazy J? Hmm...
We have machine index space, lets make a SystemSquare.
MySquare@SystemSquare,"name text who int where blob"
What did I do with the quotes? Something interesting, I said they enclosed a semi ordered set of words. Isn't that more interesting than "Don't look here" or "Some bytes" Or I suppose:
MySquare@SystemSquare,name:text.who:int.where:blob,xx
I like it, easy. Lazy J naturally parses that into binary object for @ interpreter. It look up SystemCall, System call gets the argument structure and does a fetch until the schema is done. Then courtesy of Sqlite3, it does the create.
So, in you use Lazy J as CSV files on steroids, identify a proprietary table format, up front. Then keep loading million of records, using named:value pairs, or just grouping values together. I have tested this machine with long list of variably groups key words, no problemo.
Let's make square tables, tables with many columns. Lazy J, the ninth wonder of the world.
We have machine index space, lets make a SystemSquare.
MySquare@SystemSquare,"name text who int where blob"
What did I do with the quotes? Something interesting, I said they enclosed a semi ordered set of words. Isn't that more interesting than "Don't look here" or "Some bytes" Or I suppose:
MySquare@SystemSquare,name:text.who:int.where:blob,xx
I like it, easy. Lazy J naturally parses that into binary object for @ interpreter. It look up SystemCall, System call gets the argument structure and does a fetch until the schema is done. Then courtesy of Sqlite3, it does the create.
So, in you use Lazy J as CSV files on steroids, identify a proprietary table format, up front. Then keep loading million of records, using named:value pairs, or just grouping values together. I have tested this machine with long list of variably groups key words, no problemo.
Let's make square tables, tables with many columns. Lazy J, the ninth wonder of the world.
No_sql vs the Stepping API
Consider the definition of a stepping bytecode: append_while_match. In graph languge, this is collecting from a word look up table. In @ this is Gout@"word",Dictionary. What happened to the Sql? Gone? No, underneath the Qson machine used the appropriate bytecode for the machine it compiled with. Sql developers made sure that they have great steppers, other developers will compete with different implementations of the stepping API. But Sqlite3 has the best stepper in the business right now. So underneath is the insert into Gout select key,link,1 from g2 where g1.key = g2.key; Why not?
Tuesday, February 21, 2012
Pondering the Colon
I often sit for hours plotting plans for Json Uglies. The Colon is the most interesting, how do we define it? Name:Value mans that in the current index space, the index Name return Value. The index space is likely a spanning tree over the web, clients can always index, and if their index space is detailed, and its bot update system fast; then client gets the value fairly quick. But for fast runs the client wants to use names he knows are local. How is a name invoked? I dunno for sure, but I define the formal $Name, I'll change it when someone complains.
Within an @ sequence, I will dispense with the $ altogether. I think the changes within the @, like quotes mean a bag of key words! Anyway, under the @, everything is looked up. My intent is to ultimately define the language with one statement: Gout@Gin1,Gin2, commutative with the arguments. All the Gs are graphs on the web in standard indexed form. Why? Well, really, its just an expanded definition of a bytecode. It just means, "Run the associated byte code".
The programming model greatly simplifies searches. The two arguments,Gin1,Gin2 and Gout are seen as two nested graphs, but execute as two linear sequences of bytecodes, on each other. Generally the client graph is smaller, the searched graph huge, but both obey the same rules of nesting, or shall we say, nesting up to be in a position to take a hop, or step along the graph. But the query is a simple query by example, the small graph has a little pattern it is checking that patter against the bigger graph down a certain alley of patterns. I have all the nesting I want: Name@@G1,Gin,G3 Really just nesting the bytcode interpreter.
So, the programming model is lock the machine, run the tables, and unlock the machine. Inside lock the machine there is step, step an fetch, step if match, drop if unmatched, set node equal to etc. But the machine the graphs use to interpret the byte codes is a simpler interpreter than say for JavaScript. It is a script designed to optimize short pattern matching and stepping and counting snippets.
Stepping across machines is transparent, the issuing Gin causes a pause, the entire ready state for that run is pushed, and the intermediate Qson launched. Simple graph searching/marking protocols, 30-60-200 years old work. We just want to make Json a little bit self directed.
The Qson machine is designed to do one thing, move Qsons, in complete units, through the interpreted, and send the results back. It has memory,flat, Json, and table formats, and can move these chunks very fast.
Within an @ sequence, I will dispense with the $ altogether. I think the changes within the @, like quotes mean a bag of key words! Anyway, under the @, everything is looked up. My intent is to ultimately define the language with one statement: Gout@Gin1,Gin2, commutative with the arguments. All the Gs are graphs on the web in standard indexed form. Why? Well, really, its just an expanded definition of a bytecode. It just means, "Run the associated byte code".
The programming model greatly simplifies searches. The two arguments,Gin1,Gin2 and Gout are seen as two nested graphs, but execute as two linear sequences of bytecodes, on each other. Generally the client graph is smaller, the searched graph huge, but both obey the same rules of nesting, or shall we say, nesting up to be in a position to take a hop, or step along the graph. But the query is a simple query by example, the small graph has a little pattern it is checking that patter against the bigger graph down a certain alley of patterns. I have all the nesting I want: Name@@G1,Gin,G3 Really just nesting the bytcode interpreter.
So, the programming model is lock the machine, run the tables, and unlock the machine. Inside lock the machine there is step, step an fetch, step if match, drop if unmatched, set node equal to etc. But the machine the graphs use to interpret the byte codes is a simpler interpreter than say for JavaScript. It is a script designed to optimize short pattern matching and stepping and counting snippets.
Stepping across machines is transparent, the issuing Gin causes a pause, the entire ready state for that run is pushed, and the intermediate Qson launched. Simple graph searching/marking protocols, 30-60-200 years old work. We just want to make Json a little bit self directed.
The Qson machine is designed to do one thing, move Qsons, in complete units, through the interpreted, and send the results back. It has memory,flat, Json, and table formats, and can move these chunks very fast.
Installs on my machine
Anything sql, really. One statement per operator, but you can run sequences bof them wiwith the machine locked. ure, just make a Qson file with your operators and any arguments they use:
@MyOp1,sometable.@myOp2,AnotherTable ...
Lay them out like a descent of opcodes, with the implied begin and end. Brackets work for nesting @{@A,B},{C} this should work, though I may be staring at the debugger for some time to make it so. I am reaching a truce with brackets.
Installs are formated just like other operators: @SystemInstall,opid.script.map0.map2,...
Your script could e insert into table where case union or whatever. You can pre compile them to an existing table. All courtesy of Sqlite3. Maps are ready variable that might be of interest to sql developers, maps of internal variables. And developers have local symbols available to assist.
@MyOp1,sometable.@myOp2,AnotherTable ...
Lay them out like a descent of opcodes, with the implied begin and end. Brackets work for nesting @{@A,B},{C} this should work, though I may be staring at the debugger for some time to make it so. I am reaching a truce with brackets.
Installs are formated just like other operators: @SystemInstall,opid.script.map0.map2,...
Your script could e insert into table where case union or whatever. You can pre compile them to an existing table. All courtesy of Sqlite3. Maps are ready variable that might be of interest to sql developers, maps of internal variables. And developers have local symbols available to assist.
So how is the software going you ask?
Installs is almost working, and that was the last feature for the alpha. After that is is getting the buffers under control, making sure the machine can come to a fresh start each round. So, One half bug away, then clean up and more documentation. Oxygen is great, I have no code comments except where doxygen can read them. The machine stepping API is very useful, very fast, and a very long and growing list. My machine's first task is to be the scratch base for the new network, the sponge you can fill up, squeeze and empty out. Put it anywhere, run it.
Congrats to YaCa, I am jealous! They did a great job
Congrats to YaCa, I am jealous! They did a great job
YaCy new search technology
It run a local server, on your machine, adn communicates over the YaCa network. So long Giggle and FootBooks and LinkedSpam and whatever. Here is a query cramed into the Url named parameters:
http://localhost:8090/yacysearch.html?query=better+economics&Enter=Search&verify=iffresh&contentdom=text&nav=hosts%2Cauthors%2Cnamespace%2Ctopics%2Cfiletype%2Cprotocol&startRecord=0&indexof=off&meanCount=5&resource=global&urlmaskfilter=.*&prefermaskfilter=&maximumRecords=10
Notice the host? that is local host, it is likely the one my machine uses, 127.0.0.1 The query system is built from active nodes, every computer listens and talks. Listening is no big deal, its a few bytes stored somewhere differently that is all, no energy costs as long as you use little of it. You really do not even need an IP, you just need the bots to make sure you hoe computer is indexed properly. It is a revolution, singularity stuff.
What is going on? We just boosted the IQ of the web by two or three. What we are doing is a very big deal. My graph machine wants to be part of the YaCy framework. It wants to index your searches every where, and share them, under you control. That is what YaCa wants. YaCa is open source.
http://localhost:8090/yacysearch.html?query=better+economics&Enter=Search&verify=iffresh&contentdom=text&nav=hosts%2Cauthors%2Cnamespace%2Ctopics%2Cfiletype%2Cprotocol&startRecord=0&indexof=off&meanCount=5&resource=global&urlmaskfilter=.*&prefermaskfilter=&maximumRecords=10
Notice the host? that is local host, it is likely the one my machine uses, 127.0.0.1 The query system is built from active nodes, every computer listens and talks. Listening is no big deal, its a few bytes stored somewhere differently that is all, no energy costs as long as you use little of it. You really do not even need an IP, you just need the bots to make sure you hoe computer is indexed properly. It is a revolution, singularity stuff.
What is going on? We just boosted the IQ of the web by two or three. What we are doing is a very big deal. My graph machine wants to be part of the YaCy framework. It wants to index your searches every where, and share them, under you control. That is what YaCa wants. YaCa is open source.
Here is the machine in action with a square table
Straight from the lazy J console. I type in the @ and it then knows to look up thing in th elocal space. It finds the System exec, and runs it against the following text, which becomes a bound object to the System call. The default handler for an arbitrary scrip execution is the square table handler, naturally, because that is the maximum entropy result! Square handler just gets column info and lists and output fro the exec call. Straight out of that github code, free, no patent restriction, cutnpaste license.
Init:{@SystemExec,"select * from result;"}
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
I am gonna be a gazzillionare and I have no titles after my name. I am anonymous.
Init:{@SystemExec,"select * from result;"}
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
|Txt0||Txt0||0||0||0|
I am gonna be a gazzillionare and I have no titles after my name. I am anonymous.
Brackets are my nemesis
Like the quotation mark, I am at war with them. I can keep them, keep their form and semi-redundant meaning inside Qson, no problem I just keep the null named block. But better still I can leave it to the client with the option, a client variable. If the variable is set, the client goes full tilt, minimum bracket, otherwise he Json bracket standard.
The same with quotes. The quotation mark is a disguise, it says to the micro processor, nothing to see here. They are no fun. If I designed the quotation mark, it would say more interesting things, like, look here, a semi-ordered set of medium sized key values. That would be fun.
The same with quotes. The quotation mark is a disguise, it says to the micro processor, nothing to see here. They are no fun. If I designed the quotation mark, it would say more interesting things, like, look here, a semi-ordered set of medium sized key values. That would be fun.
Sql tables everywhere
The machine will generate hundreds, thousands, millions of Qson sqlite3 tables. Right now I rely on the knowledge of the clients, he knows what tables he gets and puts. Then files everywhere, this thing reads Json like CSV on steroids, with variable length rows ad ad hoc naming. So Json has placed CSV.
I get stuck as the software geek. Every Json that enters the system has to be named inthe local table index space. That would be sqlite_master, I presume.
Naming spaces are web wide, though often sparse for some applications. They are indices, and for a table, they have to include and ip or url. So an entry into a server, will cause a migration out of updates. So every reference to a table is bound with it potentially web wide presence, it has to be specific. Hmm... can this wait until we get the machine out, then folks will play around with the problem. Yes, set this up for beta, for alpha its local tables only, and client knowledge of where things are. Right now I routinely load Json word lists, I should upload one of these for testing. They are variable length groups of words.
What the client sees:
The client bookmark, for example, he may think they are local. But in the extended pakage, the provider can extend his bookmarks closer to data. Or the client can drag his book marks to the local server they travel. Bookmarks are web tags, literally, they are table you own somewhere on some server sqlite platform. It is like controlling names Json space in the web, and you have developer provided tool to fill this indexed space with goodies.
Anyway, naming is infringing on those right assigned to others, once again.
I get stuck as the software geek. Every Json that enters the system has to be named inthe local table index space. That would be sqlite_master, I presume.
Naming spaces are web wide, though often sparse for some applications. They are indices, and for a table, they have to include and ip or url. So an entry into a server, will cause a migration out of updates. So every reference to a table is bound with it potentially web wide presence, it has to be specific. Hmm... can this wait until we get the machine out, then folks will play around with the problem. Yes, set this up for beta, for alpha its local tables only, and client knowledge of where things are. Right now I routinely load Json word lists, I should upload one of these for testing. They are variable length groups of words.
What the client sees:
The client bookmark, for example, he may think they are local. But in the extended pakage, the provider can extend his bookmarks closer to data. Or the client can drag his book marks to the local server they travel. Bookmarks are web tags, literally, they are table you own somewhere on some server sqlite platform. It is like controlling names Json space in the web, and you have developer provided tool to fill this indexed space with goodies.
Anyway, naming is infringing on those right assigned to others, once again.
Monday, February 20, 2012
Things that go IO in software
Sending something someplace in software involves a variety of io systems with differing specs on what constitutes th destination pointer. Files like "c:/soft" and stdio and FILE *, sockets have fd, they have "127.0.0.1" and PORT, And they all might have a protocol family: text or binary. The total necessary components to hold them all is the inner join of them with context definition for some variables.
So I have this container, it can have address, family type, fd, void * to something. It is set up to fit socket standards at the base, and build one or two items above that after padding. One single chunk of memory that has variable access for any type of destination. Its work to fill variable values, but the container holds space. I call it the generic Webaddr, but might change the name to IO_Thing. It's important because the machine always needs to flush things outward, and move itself back to empty.
So I have this container, it can have address, family type, fd, void * to something. It is set up to fit socket standards at the base, and build one or two items above that after padding. One single chunk of memory that has variable access for any type of destination. Its work to fill variable values, but the container holds space. I call it the generic Webaddr, but might change the name to IO_Thing. It's important because the machine always needs to flush things outward, and move itself back to empty.
Our web bots control their own naming space on the web
The name value pair, name:value, the thing that makes Json famous, those names belong to the clients who issued the bot in which it appears. A bot can names anything it finds on the web, in its own name space. How well that name space responds to requests depends o the clients pocket book.
so, things like, {MattsIP:$MyLocalIP} says my index space registers my local IP when ever MattsIP is referenced in my space. Everywhere? Sure, but how? A bot is launched, a bot dedicated to keeping my address space up to date. So I am not worried. My friends, who have some read access to my index space, can say: $MattsIP@{Sendto,SomeGreatDomTree}
Vendors will use my machine, by hitting a few key strokes, then start hiring sql programmers like mad. Sql programmers who can maintain a distributed naming space over the domain will be in demand.
The shear ingenuiity of clever programers will allow groups to atually have their own shared tables across the 'world' (across the warehouse of linux boxes in the North Pole). But groups could autonomously form, making poor the new gazillionares of out age (except me, of course). This is going to be fun, the machine will load up the local symbol table on demand, put it into the qsort/bsearch default table in memory; for the duration of a bot run. Pure freedom from the web monopolists. Super fast, blazing speeds, huge capability in configurations, but completely independent of anything except stdio, sqlite and sockets.
so, things like, {MattsIP:$MyLocalIP} says my index space registers my local IP when ever MattsIP is referenced in my space. Everywhere? Sure, but how? A bot is launched, a bot dedicated to keeping my address space up to date. So I am not worried. My friends, who have some read access to my index space, can say: $MattsIP@{Sendto,SomeGreatDomTree}
Vendors will use my machine, by hitting a few key strokes, then start hiring sql programmers like mad. Sql programmers who can maintain a distributed naming space over the domain will be in demand.
The shear ingenuiity of clever programers will allow groups to atually have their own shared tables across the 'world' (across the warehouse of linux boxes in the North Pole). But groups could autonomously form, making poor the new gazillionares of out age (except me, of course). This is going to be fun, the machine will load up the local symbol table on demand, put it into the qsort/bsearch default table in memory; for the duration of a bot run. Pure freedom from the web monopolists. Super fast, blazing speeds, huge capability in configurations, but completely independent of anything except stdio, sqlite and sockets.
Patent trolls don't scare me
Intellectual Ventures occupies a special place among patent holding companies. The company has for years been amassing thousands of patents and inviting companies to become “investors” in its investment funds. Critics say the practice amounts to extortion and describe I.V. as a giant patent troll.
Read more: http://paidcontent.org/article/419-goliath-vs.-goliath-patent-beast-intellectual-ventures-sues-att/#ixzz1mw8eNib2 Time Business
The patent troll has one big problem, software goes anywhere, almost on its power. Ultimately they have to chase down every last user who has down loaded from a share file server. The micros are fast, damn fast. So they are all programmed and the software replaceable.
And of course, I make sure of 30 years of prior art, build the result around a base that 30 years. From there I retain the semantics of the prior art.
Where to send the output?
The machine, in my version of Json search, does the following join:
C@{A,B}
There is always a C result, even if null. The residual contains the return address, the machine wants to pick up the residual and return it to the owner and be done, empty once again. So emitters of Qson often get null returns, they should just dump them, or track but don't respond.
Who cares? Me, I need to test this thing, and fear treading in syntax grounds where I don't belong. I don't want to look stupid when smarter folks do it much better than I.
But I need to do lots of: Start2@Start1@Test,SystemSend,SystemSend
You know, the really and truly bizarre, so bizarre that only the truly stable machine passes. I want simple Json control strings that move files and tables and networks, running lots of them with different instances and Jsons sending stuff. The true test is the amount of intelligent disk head flutter I can create. I want a simple syntax to do that, so I have holding off and off, for fear of adapting a kludge without thought or feedback.
C@{A,B}
There is always a C result, even if null. The residual contains the return address, the machine wants to pick up the residual and return it to the owner and be done, empty once again. So emitters of Qson often get null returns, they should just dump them, or track but don't respond.
Who cares? Me, I need to test this thing, and fear treading in syntax grounds where I don't belong. I don't want to look stupid when smarter folks do it much better than I.
But I need to do lots of: Start2@Start1@Test,SystemSend,SystemSend
You know, the really and truly bizarre, so bizarre that only the truly stable machine passes. I want simple Json control strings that move files and tables and networks, running lots of them with different instances and Jsons sending stuff. The true test is the amount of intelligent disk head flutter I can create. I want a simple syntax to do that, so I have holding off and off, for fear of adapting a kludge without thought or feedback.
My market, a straight shot to Json
In the Qson system, this code, right here, is shuffling data from Sqlite3 to whatever Json receiver want it, console, network, or file. But this is high speed stepping through a Qson table using Sqlite embedded function call, prepared statements, and high speed bindings. If you want Json fast, want it searchable, want it free and simple; what can I say?
int table_to_Json(TABLE *t,Webaddr * to) {
int len; int i,rows;
Triple Qin;char * key_value;char tmp[9];
Code stmt;
stmt = start_table(t,pop_operator);
// peek at the header
i = machine_step_fetch(&Qin,0);
rows = Qin.pointer;
for(i=0;i<rows;i++) {
if(i) machine_step_fetch(&Qin,0);
len = machine_key_len(stmt);
send_(Qin.key,len,to);
send_(tmp,sprintf(tmp,"%c",Qin.link),to);
}
This transmission automatically closes on balanced brackets.
How is the software going you ask?
Actually stable enough for me here at home to load lots of words via the console, and move them around. I don't fix all known bugs unless demand makes me. I often leave a bug if it is no bother at home. But over time, I up load the bugs I fix. I am about five bugs away from someone taking this to their company and cramming Json files at it.
Sunday, February 19, 2012
Doxygen I am hooked
The best documentation extractor for source code. Doxygen, second best thing since apple pie. Folks who want documentation just get Doxygen, and run the code through that. Nothing more than doxygen and reasonable coding practices. I run doxygen through my header files only, I see everything that is exported.
Saturday, February 18, 2012
Native Qson Formats
There are four forms of Qson, sqlite table, in memory graph, flat format for files and sending, and Json. The code comes with a run time switch, you can go from any to any. Any file to/from any table to/from any network to/from any console to/from any memory. What about the flat file for sending? here is a complete example (I did by hand):
POST\r\nContent-Type:text/qson\n\rContent-Length:00000029+00200041234,10003123
So everything up through the colon is magic fixed size header. Then eight bytes of content length (the Endianess thingy can be adjusted). Then, for each triple; three bytes of row count, and key_count and key_bytes. This is all subject to change, of course. The more likely is that link gets four bytes, and pointer gets four and key count gets four, and data is a minimum of four. So the graph of one node is 16 bytes, the minimum atomic unit. Then make the total count an eight byte value, but it counts in big units of eight bytes at a time. The minimum additional key data increment becomes eight bytes, and a twelve byte string (zero terminator not needed) for a name become perfect.
MyWebAddress,is a twelve bytes index into a table maintained by your service provider. The provider can add: CheapSeats$MyWebAdress , indicating you are a dead beat CutnPaster, like me. CheapSeats point to a secondary look up table. The syntax here is still under discussion, it will be what works the fastest and most efficient in the engine itself. Keep short names is not a requirement, but a foreknowledge that clients learn.
The in memory format is an array of triples struct {int;int,int*;} and the key pointer points to buffs containing key_count,key_data.
The sqlite format is a three column: link,pointer,blob Sqlite wants the blob move to the last column, and it also means the engine can caste the triple format onto a buffer and match the variable names. So all formats keep key_count,key_bytes last.
For Json its all about replacing the key_count with brackets and colons appropriately. Going the other way is Lazy J.
That is the plan, subject to change for native Qson.
POST\r\nContent-Type:text/qson\n\rContent-Length:00000029+00200041234,10003123
So everything up through the colon is magic fixed size header. Then eight bytes of content length (the Endianess thingy can be adjusted). Then, for each triple; three bytes of row count, and key_count and key_bytes. This is all subject to change, of course. The more likely is that link gets four bytes, and pointer gets four and key count gets four, and data is a minimum of four. So the graph of one node is 16 bytes, the minimum atomic unit. Then make the total count an eight byte value, but it counts in big units of eight bytes at a time. The minimum additional key data increment becomes eight bytes, and a twelve byte string (zero terminator not needed) for a name become perfect.
MyWebAddress,is a twelve bytes index into a table maintained by your service provider. The provider can add: CheapSeats$MyWebAdress , indicating you are a dead beat CutnPaster, like me. CheapSeats point to a secondary look up table. The syntax here is still under discussion, it will be what works the fastest and most efficient in the engine itself. Keep short names is not a requirement, but a foreknowledge that clients learn.
The in memory format is an array of triples struct {int;int,int*;} and the key pointer points to buffs containing key_count,key_data.
The sqlite format is a three column: link,pointer,blob Sqlite wants the blob move to the last column, and it also means the engine can caste the triple format onto a buffer and match the variable names. So all formats keep key_count,key_bytes last.
For Json its all about replacing the key_count with brackets and colons appropriately. Going the other way is Lazy J.
That is the plan, subject to change for native Qson.
debug define comments
In he lab, working the core issue, I just use printf extensively, even in testing components. Code is spaghetti, in the lab the correct model is none, if you had a coding model you wouldn't be in the lab, by definition, IMO. Then you want the thing available for production use. Your printfs become DebugPrint, a macro you can turn off and on. When turned on, they print certain key variables, not just any old random variable.
The the comments need to be formalize, or even added in my case. I rarely use comments in the lab. But then the real thing comes, other developers need the instruction to avoid the reverse engineer problem. So you formalize the comments a bit,a regular one lines, of ten lines devoted to a section or module. And, mark your comments with something, preferably the industry standard comment marker that allows for extraction onto a web manual.
Easy, fun work; more fun then staring at some three level structure pointer collision in the debugger. Way more fun than debugging.
The the comments need to be formalize, or even added in my case. I rarely use comments in the lab. But then the real thing comes, other developers need the instruction to avoid the reverse engineer problem. So you formalize the comments a bit,a regular one lines, of ten lines devoted to a section or module. And, mark your comments with something, preferably the industry standard comment marker that allows for extraction onto a web manual.
Easy, fun work; more fun then staring at some three level structure pointer collision in the debugger. Way more fun than debugging.

Back to graph stepping
The machine up their at github, it has a memory form of Qson, the closely compact association of key link,pointer, and key value; all together. Very fast stepping through a search graph in memory. The machine knows that, direct the key word match to an sql operator, wiht a search coll back. On call bak, tjust maintin the search pointers for the memory graph. Using insert select case union, the operator could rapidly zoom through the search graph, against a very huge database. You know, designed to zip whole Qson graphs around, so we get hybrid version of the general join. Service providers using encryption gate way nodes to collect pennies for a thousand hops.
But you get a myriad ways of looking, each efficient, each with a market. If clients agreed to 16 byte words limits, the machine could have that immediate key property, and always kick in higher speed search due to shorter guarantees on key length. You local machine could have very complicated info stored in a variety of ways. But knowing you will be limited to 16 byte key words makes all that info available instantly. Vendors of data and vendors for B tree technology will cooperate, making huge stores readily available at the home machine. The engine developers will compete for the best browser B tree, they will come up with amazing stuff, knock our socks off. They just attach their B tree machine to the grammar engine.
But you get a myriad ways of looking, each efficient, each with a market. If clients agreed to 16 byte words limits, the machine could have that immediate key property, and always kick in higher speed search due to shorter guarantees on key length. You local machine could have very complicated info stored in a variety of ways. But knowing you will be limited to 16 byte key words makes all that info available instantly. Vendors of data and vendors for B tree technology will cooperate, making huge stores readily available at the home machine. The engine developers will compete for the best browser B tree, they will come up with amazing stuff, knock our socks off. They just attach their B tree machine to the grammar engine.
What we will create
Millions of disk heads fluttering near the North Pole in huge warehouses. Seriously. But then comes the overwhelming gain buy connecting these fluttering disk heads to real micro bots around the world.
Modeling the join on the command line
The starting point with this generalized join is that the machine can step two graphs together. This process is enabled with the @ So that character riggers the system to go into binary op mode as in result@{A,B} Right away Lazy J want to drop the brackets when it sees the @ char, so lets to that. Start with some simple forms:
@_,_ // return the console prompt, this is two null graphs
@MyTable,_ // return mygraph in json form (currently)
OK, so right away, my claim is that on seeing the @, the ugly handler loads the table names from sqlite_maser into the local symbol set. After that, the default is a key word expresses a local table, as a variable. Watch your graph names or be prepared to quote a whole damn lot.
The in @ mode we allow: @config,SysemConfig configuration table run straight into the machine should be OK. Then comes this: @{"key key key2 key5",dictionary} Can it do that!
Not yet, what we need is a way to tell Lazy J to mark a set of key words as immediate, not look ups, and do that silently. A better quote character says, each element in the quotes is a space delineated key word. Define {"k1,k2.k3,k4"} as a valid graph in the k# set, in the quotes. But the key is silently overloaded to be a key word matchable type. The ugly handler knows not to look it up. Something akin to the Bson cstring names, something designed to be navigation fast, like it mostly fits immediately in the B-tree system. Clients know the price goes way up when key name terminals get longer than 32 characters. Look at a search syntax: @"word1,word2.word3",bookmarks,news Hey, we're dumping the uglies, it almost looks human. That @ just looks like a substitute for the Giggles advanced search button, huh?
VC should fund Imagisoft, and we would hire the pros to design the optimum B tree system for graph hopping.
Anyway, so the binary system gets me anything in graph context that we had in unix command line. We can do: @A,@B,{c.@B,d} Get the pipe thing going. Especially with high speed Qson IO, and ultra high speed in memory Qson, the ability to move Qson makes using tables in expressions work. My favorite will be: @test,SystemDebug
@_,_ // return the console prompt, this is two null graphs
@MyTable,_ // return mygraph in json form (currently)
OK, so right away, my claim is that on seeing the @, the ugly handler loads the table names from sqlite_maser into the local symbol set. After that, the default is a key word expresses a local table, as a variable. Watch your graph names or be prepared to quote a whole damn lot.
The in @ mode we allow: @config,SysemConfig configuration table run straight into the machine should be OK. Then comes this: @{"key key key2 key5",dictionary} Can it do that!
Not yet, what we need is a way to tell Lazy J to mark a set of key words as immediate, not look ups, and do that silently. A better quote character says, each element in the quotes is a space delineated key word. Define {"k1,k2.k3,k4"} as a valid graph in the k# set, in the quotes. But the key is silently overloaded to be a key word matchable type. The ugly handler knows not to look it up. Something akin to the Bson cstring names, something designed to be navigation fast, like it mostly fits immediately in the B-tree system. Clients know the price goes way up when key name terminals get longer than 32 characters. Look at a search syntax: @"word1,word2.word3",bookmarks,news Hey, we're dumping the uglies, it almost looks human. That @ just looks like a substitute for the Giggles advanced search button, huh?
VC should fund Imagisoft, and we would hire the pros to design the optimum B tree system for graph hopping.
Anyway, so the binary system gets me anything in graph context that we had in unix command line. We can do: @A,@B,{c.@B,d} Get the pipe thing going. Especially with high speed Qson IO, and ultra high speed in memory Qson, the ability to move Qson makes using tables in expressions work. My favorite will be: @test,SystemDebug
So lets talk the inner join
My claim is that the inner join, and all other software atomics, can be viewed as a mutual traversal by two graphs, so my generalized lambda operator fr Lazy J becomes the @, You don;t always have to type it, often your environment knows it.
as in:
MyResults@{ {word1,word2,word3},SomeTableOfWords}
Get you a Qson full of results, ship it right back. But lets talk the wild cards. First null:
@words,_
Run something called words along the null graph. Probably the null behavior his is to echo whatever words is. What is the default way for the machine to figure out words? The machine, being what it is, would think words are a table, by default, and if not, then some immediate string constant. So, in the default, just type the table name, and it regurgitates. How about this:
@config,SystemInstall
One would expect the machine to look up config as a table, and would certainly know what SystemInstall is, right? I dunno, tying for the very simple, as usual. But the idea here is that under the @ operator, natural symbols for the machine come into play, it has a more liberal use of symbols.
Hey, what about dropping syntax uglies like I do? Why not, or why not connect up better shell, one that emits Json into the machine?
as in:
MyResults@{ {word1,word2,word3},SomeTableOfWords}
Get you a Qson full of results, ship it right back. But lets talk the wild cards. First null:
@words,_
Run something called words along the null graph. Probably the null behavior his is to echo whatever words is. What is the default way for the machine to figure out words? The machine, being what it is, would think words are a table, by default, and if not, then some immediate string constant. So, in the default, just type the table name, and it regurgitates. How about this:
@config,SystemInstall
One would expect the machine to look up config as a table, and would certainly know what SystemInstall is, right? I dunno, tying for the very simple, as usual. But the idea here is that under the @ operator, natural symbols for the machine come into play, it has a more liberal use of symbols.
Hey, what about dropping syntax uglies like I do? Why not, or why not connect up better shell, one that emits Json into the machine?
How your web bot steps along the web
I think the marketing term should be Qbots, made of Qsons, walking the graph.
The concept here is that your bot wants to take a step up the web graph, and that consumes web resources. the Web graph wants a match, it needs at the minimum a key word match between its gateway node and your search graph head. The model here is that your gets gets permission to step up the web, taking its itself along, naturally.
This concept of stepping, your bot stepping a cursor through itself, and another bot stepping a cursor along itself. Each cursor will step if the match conditions are correct. This is the generalized join, and with wild cards of certain sorts at either graph, outer lefts and right can be constructed.
In the engine, this is a very fast process, ultimately done in compiled sqlite3 code, which is designed to step along graphs. Keywords zoom though key word tables. But it can be slow at gateways, as slow as getting your encryption key processed.
The engine right now is very good at stepping along one graph at a time, as if the other graph was always stationary, a wild card that self steps in place and reports yes. Filling a table is three step process.
machine_new_operator(table,append);
while(more){
machine_append(triple);
triple++;
}
I have a switch, it will move Qson bundles anywhere, under windows or unix. Qbots can hop around.
The concept here is that your bot wants to take a step up the web graph, and that consumes web resources. the Web graph wants a match, it needs at the minimum a key word match between its gateway node and your search graph head. The model here is that your gets gets permission to step up the web, taking its itself along, naturally.
This concept of stepping, your bot stepping a cursor through itself, and another bot stepping a cursor along itself. Each cursor will step if the match conditions are correct. This is the generalized join, and with wild cards of certain sorts at either graph, outer lefts and right can be constructed.
In the engine, this is a very fast process, ultimately done in compiled sqlite3 code, which is designed to step along graphs. Keywords zoom though key word tables. But it can be slow at gateways, as slow as getting your encryption key processed.
The engine right now is very good at stepping along one graph at a time, as if the other graph was always stationary, a wild card that self steps in place and reports yes. Filling a table is three step process.
machine_new_operator(table,append);
while(more){
machine_append(triple);
triple++;
}
I have a switch, it will move Qson bundles anywhere, under windows or unix. Qbots can hop around.
Friday, February 17, 2012
Windows sockets, up and running
It was a CutnPaste from the web got it going. We need an anonymosu CutnPaste tip jar for the web! Thee should be more compensation than an entry into my random pages bookmark folder.
Anyway, that means I can just create a send Qson routine, and the machine don't care who sends. Underneath the send and listen we do is so simple we just implement both windows and Linux mode. So I am going to start running in full network mode all the time. So, in about five hours I will have this thing compiling in either mode.
Anyway, that means I can just create a send Qson routine, and the machine don't care who sends. Underneath the send and listen we do is so simple we just implement both windows and Linux mode. So I am going to start running in full network mode all the time. So, in about five hours I will have this thing compiling in either mode.
Using the machine for bookmarks
How about:
bookmarks:{science:{url1,url2,url3},music:{Etc},...}
A big file of these. You send that script, yes, right there, with a cutnpast into the Json console, and they go to your bookmarks table. How do you list them at them console? Hmm.. How about:
bookmarks
We let you skip the brackets, your default symbol set is working, You type the table name you want, you get it. Qson, and Lazy J with the power of Sqlite3 I can make this sing with R! Hmm.. When you search for the days news, use this:
@{bookmarks,todayslink}
todays links is a set of keywords generated by the data aggregaters. They 'borrow' you book arks and look for certain key words through your links. A lot of this stuff will happen as the natural grammar of inner joins, as seen through the graph model. Stepping graph one, or both or back stepping one or both, via default matches on key words.
Seriously, fun stuff.
bookmarks:{science:{url1,url2,url3},music:{Etc},...}
A big file of these. You send that script, yes, right there, with a cutnpast into the Json console, and they go to your bookmarks table. How do you list them at them console? Hmm.. How about:
bookmarks
We let you skip the brackets, your default symbol set is working, You type the table name you want, you get it. Qson, and Lazy J with the power of Sqlite3 I can make this sing with R! Hmm.. When you search for the days news, use this:
@{bookmarks,todayslink}
todays links is a set of keywords generated by the data aggregaters. They 'borrow' you book arks and look for certain key words through your links. A lot of this stuff will happen as the natural grammar of inner joins, as seen through the graph model. Stepping graph one, or both or back stepping one or both, via default matches on key words.
Seriously, fun stuff.
The two marketing points
Lazy J and Qson. I love it, a great laugh, an really good by the way. There are lots of things to do with the Lazy J console, like preload a symbol table, and put all key names to the table. What does this mean:
MySymbols${A bunch of Json Text }
I think it means refer to MySymbols, some symbol table somewhere. How about that !! Lazy J lets you push and pop look up tables at the console.
And the phenomenal ability to move Qson bundles everywhere, file, table, memory, network, console. When, when you want em, they appear as Json or Bson, but you will always want them as Qson, cause you have the Sqlite3 machine. We can directly load your Dom tree with Qson bundles, and you wouldn't want to leave you Dom tree empty.
I'm work ease of use at the moment, the part I like.
MySymbols${A bunch of Json Text }
I think it means refer to MySymbols, some symbol table somewhere. How about that !! Lazy J lets you push and pop look up tables at the console.
And the phenomenal ability to move Qson bundles everywhere, file, table, memory, network, console. When, when you want em, they appear as Json or Bson, but you will always want them as Qson, cause you have the Sqlite3 machine. We can directly load your Dom tree with Qson bundles, and you wouldn't want to leave you Dom tree empty.
I'm work ease of use at the moment, the part I like.
Thursday, February 16, 2012
A Lazy Json example
How things woked out finally:
$SystemCopy{Table$MyTable.File$MyFile}
That works in full Qson mode, and does what we expect. The $ here is over utilized, it say, look up system copy. System copy moves a Qson from one place to another.
Table&MyTable, find MyTable in the table index, and so on.
If you set up the call:
MyTable:Table$MyTable. $SystemCopy{MyTable,MyFile}
Does it work? Dunno, yet.
$SystemCopy{Table$MyTable.File$MyFile}
That works in full Qson mode, and does what we expect. The $ here is over utilized, it say, look up system copy. System copy moves a Qson from one place to another.
Table&MyTable, find MyTable in the table index, and so on.
If you set up the call:
MyTable:Table$MyTable. $SystemCopy{MyTable,MyFile}
Does it work? Dunno, yet.
If I could make one change to the Bson spec
I would sa that names work either as c strings or the formal string with a byte count. Let the Bson parser choose the proper format, and force and c string name to be a counted string when the byte count is greater than 15. In other words, let the parser be intelligent about using the optimum format.
I will definitely become a gazillionare
1. Informatics for adding value to information
The quantity of information now available to individuals and organizations is unprecedented in human history, and the rate of information generation continues to grow exponentially. Yet, the sheer volume of information is in danger of creating more noise than value, and as a result limiting its effective use. Innovations in how information is organized, mined and processed hold the key to filtering out the noise and using the growing wealth of global information to address emerging challenges.Top Ten Technologies
Wednesday, February 15, 2012
Qson and the life cycle of Sqlite3 tables
It is becoming clear that a Sqlite3 table is initialized and table operators set up for the complete run of the table through the machine. So the application inits the table, then steps the machine in one of a few different style loops. Their is a table context that holds the sqlite3 stmt. The ready set is prepared with row counters an limits, stmt pointer, return address, and any state variables that allow the machine to keep the stmt running.
The intent of the grammar is to release control back to the underlying sqlite3 as much as possible. So the grammar flows sqlite3 tables, they are rapidly created and consumed as scratch tables. Based on the binary convolution model between two graphs, each of which may be the null. The graph code always runs sqlite3, in all its nested glory, to completion, reaching the final return address, canceling events as fast as possible down the loops.
Is world is a descending counts of
So the software API is becoming clearer:
The grammar must provide application access, ultimately, to how the machine is stepped, short or long loops, just grab the next row, grab a count of rows, run a new operator, etc; Api based on the concept of Graph:Subgraph, limited to two at a time. The initialized graph becomes the key anchor between the grammar and the sqlite3 table.
The intent of the grammar is to release control back to the underlying sqlite3 as much as possible. So the grammar flows sqlite3 tables, they are rapidly created and consumed as scratch tables. Based on the binary convolution model between two graphs, each of which may be the null. The graph code always runs sqlite3, in all its nested glory, to completion, reaching the final return address, canceling events as fast as possible down the loops.
Is world is a descending counts of
Web:Table:Row.Canonically stated as:
Anchor:Graph:SubGraph
So the software API is becoming clearer:
The grammar must provide application access, ultimately, to how the machine is stepped, short or long loops, just grab the next row, grab a count of rows, run a new operator, etc; Api based on the concept of Graph:Subgraph, limited to two at a time. The initialized graph becomes the key anchor between the grammar and the sqlite3 table.
Bson has one effiiciency that Qson doesn't
Bson names are generally shorter than the data, so Bson makes then c strings, their total storage is much less when we can assume short strings. From the point of view of a query syntax with joins, the grammar of joins, it goes easier when the name structure looks mostly like any other structure. This is a trade off, structured and jin ready, ro compact and requiring more byte counting. For a short name with eight letters, Qson will waste about 30 bytes, total I imagine, including B tree inefficiency. When the key is always a blob, sqlite3 has the character count, always handy from beginning to end. That recovers a lot of the inefficiency in the B Tree. But native Qson sends over the wire will be bloated compared to Bson, the more naming the more bloated. But Bson still has the forward count or pointer, so fundamentally they still make Bson convolution work.
The native bundle format for Qson is:
|KeyLen|KeyData|Link|RowCount|
Qson maintains the row count, the size of the enclosed object, and the key length keep with key data. So, between machines, Qson just shuffles in an out. Qson count in rows and byte counts. But look at the waste of space when a key is a short name. In local memory, the key data is stored with malloc, and the output system can stream inefficient malloced buffers to the socket.
But that is a small trade compared to the power of being able to name data points arbitrarily along its length, andthen have an efficiet indexing on the name.
The native bundle format for Qson is:
|KeyLen|KeyData|Link|RowCount|
Qson maintains the row count, the size of the enclosed object, and the key length keep with key data. So, between machines, Qson just shuffles in an out. Qson count in rows and byte counts. But look at the waste of space when a key is a short name. In local memory, the key data is stored with malloc, and the output system can stream inefficient malloced buffers to the socket.
But that is a small trade compared to the power of being able to name data points arbitrarily along its length, andthen have an efficiet indexing on the name.
MinGW to the rescue
It has the simplest method of allowing me to compile to enough Posix to test. The simplicity engineering comes to play. If you can sift through the complicated automation, and get down to the simple thing they automated, then things work.
Dumping Windows
it is the only way forward if one is developing server software. One has to go to Linux entirely.
Cygwin is broken
They did something in the recent list o make shared libraries go missing. Why they need shared livbraries for the gcc is beyond me, but there is no way to find out what is going on since only god knows what other tools and libraries are missing.
You really can't put a Posix environment on Windows, Bill Gates permanently crewed the system up.
You really can't put a Posix environment on Windows, Bill Gates permanently crewed the system up.
Windows, mingw vs cygwin, and I am in a pickle
The general advice on Linux environemnt is type hyrogliphics and download may combination of imcpomatible items.
Often you choice is to reload the 12 Mbytes again, or plow into 30 pages to get one necessary command line. I have five ways to do Linux, all of them do it half way.
I tried Umubutu the linux thing, but it got into a boot with with Windows and lost.
I need one application. This application erases everything and downloads the last thing that worked! The every time you need to do a task, erase everything and just down load a working thing!
Often you choice is to reload the 12 Mbytes again, or plow into 30 pages to get one necessary command line. I have five ways to do Linux, all of them do it half way.
I tried Umubutu the linux thing, but it got into a boot with with Windows and lost.
I need one application. This application erases everything and downloads the last thing that worked! The every time you need to do a task, erase everything and just down load a working thing!
Why Qson is the best idea since Apple Pie
Qson separates the fixed length graph vaiables from the variable length key values. Being based on rowid, Qson presents a natural method for high speed indexing along graphs, its makes possible a separate mechanism for rowid mechanisms, so fast, that rewriting a graph is more like shuffling an array, of triplets. I can easily envision a machine that could insert and delete section of whole sub graphs, and leave key value garbage management for later. The optimum Q machine.
We get very high speed stepping by indexing, with a potential variety of ways. Code blocks with intelligent argument matching, actually very competitive parallel processing. They come in nested chunks. In the case of this machine, it can point Sql to any nested chunk in any table and run the rows on two table at a time. For a parallel, that means shared memory is ready to go, the chunks are nested, exchahnge positions at the match points using the complete and closed grammar. gain, parallel locking comes with the forward looking graph pointers and block identifiers.
Qson, fast, intelligent and compatible with any browser that talks Json, which is any browser!
We get very high speed stepping by indexing, with a potential variety of ways. Code blocks with intelligent argument matching, actually very competitive parallel processing. They come in nested chunks. In the case of this machine, it can point Sql to any nested chunk in any table and run the rows on two table at a time. For a parallel, that means shared memory is ready to go, the chunks are nested, exchahnge positions at the match points using the complete and closed grammar. gain, parallel locking comes with the forward looking graph pointers and block identifiers.
Qson, fast, intelligent and compatible with any browser that talks Json, which is any browser!
When the urge to bailout is overwhelming
If you recall, the Budget Control Act said that if the "super committee" wasn't able to come to an agreement, there would be an automatic spending cut in the amount of $1.2 Trillion dollars over the next ten years. Well, clearly the super committee fell flat on it's ass, and therefore we should see $1.2 Trillion in debt reduction when reviewing the new budget proposal -- right? Obviously this wasn't the case. Perhaps the law has "vaporized", similar to the missing MF Global funds (and the middle class). ZH
Tuesday, February 14, 2012
I nominate the name Qson
The name replaces Sqlson, too many syllables. Then we have this great marketing ploy, we can say, open source, untrademarked, unpatented, simple short code runs with the most pomerful Btree manager in the market, damn free.
Key feature:
Full support Bson,Json,Qson; I and O at high speed,
Full indexing on all named terms
Full SQL schema support within Lazy Json syntax.
Full query by example, including two variation of wild card
Full default join between any two Qson.
Runs on any Linux box
Unlimied Free remote Json consoles with each free unlimited download.
Sqlite3 power engine underneath
ACID locks on complete sub graph level.
High speed machine to machine distributed computing
Install sophisticated, proprietary sql routines, assign them to simple Json names.
Down load the amalgamation, do a gcc on it, and run it.
One week to delivery, or five bugs from alpha production release.
Key feature:
Full support Bson,Json,Qson; I and O at high speed,
Full indexing on all named terms
Full SQL schema support within Lazy Json syntax.
Full query by example, including two variation of wild card
Full default join between any two Qson.
Runs on any Linux box
Unlimied Free remote Json consoles with each free unlimited download.
Sqlite3 power engine underneath
ACID locks on complete sub graph level.
High speed machine to machine distributed computing
Install sophisticated, proprietary sql routines, assign them to simple Json names.
Down load the amalgamation, do a gcc on it, and run it.
One week to delivery, or five bugs from alpha production release.
Service providers reselling IPV6 address space
Sure, why not, within their own sub network. This machine has been adapted to accept a generic web address, which can be ip6. The machine can map them for sql insert, select and compare with installed operators. Use the assigned ipv6 addresses as indices into reserved table space. Resell table space on ad contracts.
There would exist a huge market for indexed space in the cloud, protected table space where enterprises manage their own tables and indices, using B/J/Sql sons ACID transactions. Developers would be permanently employed, forever arriving at net methods of graph arrangements to give companies the edge in timely information. The browser widgets arriving naturally.
Anyway, a few bugs away from production alpha. At that point I can dump it on any remote Linux box and begin trying scratch base kind of large object transactions.
There would exist a huge market for indexed space in the cloud, protected table space where enterprises manage their own tables and indices, using B/J/Sql sons ACID transactions. Developers would be permanently employed, forever arriving at net methods of graph arrangements to give companies the edge in timely information. The browser widgets arriving naturally.
Anyway, a few bugs away from production alpha. At that point I can dump it on any remote Linux box and begin trying scratch base kind of large object transactions.
The production alpha
This is the point when the product moves to a kind of experimental real world test, like having the code dropped into a university lab, just to play with. So you want the code to be easy, just compile the amalgamation with gcc, and run it; the Json console should come up with the default local host, ad default Sqlite3 database name. The Json remote terminal should work. The default grammar looks much better with the : and $ acting as an inverse of the other. The new opaque address will work great, and I have a mapper for it, we can build an operator to map incoming addresses, adding user protection by encryption later. Installs look very simple, syntactically. Netio got its new send Bson, and with the addr type, the cost was tens of lines, no more. Symbols work great, lock and unlock making wonderfully fast table runs. Production alpha, I have to stop the changes.
I have all the Imagisoft sales force looking for the perfect product linux lab, ready to experiment.
I have all the Imagisoft sales force looking for the perfect product linux lab, ready to experiment.
Subscribe to:
Comments (Atom)