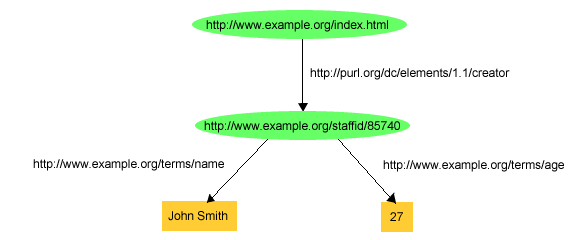
How would we do a schema in the ontology engine? How about this:
Gout = convolve(schemaID.user graph, Schemas)
The schema graph has the smarts to match the schema, then is will descend a path tat can perform what ever action the schema requires. So, the human can pick the schema he thinks works, locate that schema and have the actions desired executed as an convolution.
My point here is that adding an predicate ID to the link helps nothing. This is a case of the complexity engineers inventing complexity for no apparent reason.
No comments:
Post a Comment