We need that.
Developers agree on, say the lib.a archive format. Then design the module repository. Here is how it works:
I want to use an API I found on the web. I select and drag the object from my browser to the repository handler.
The repository handler is smart, it reads the module and extracts the version number and name and source web site, then dumps the lib onto the directed graph of libs. All my programs have one lib path, the repository. If the repository refers to your local directory, that is fine, but repository maintains its own directed graph index. At any time the developer can click and drag the modules around on the directed graph, changing the search length.
The linker should already be partitioned from the module search, so add the repository facility to the link, it can step and skip through locating the missing symbols.
Wednesday, October 31, 2018
Proof of concept
My html text file, actual plain text in bold:
<html>
htmltext starting
<body>
<font> Font text
<b> Bold text </>
<h1> header is now <b> bold</></>
</font>
<script> Script text </script>
<h1> Another header is now <h> header embedded</></>
Body text
</body>
html ending
</html>
<html>
htmltext starting
<body>
<font> Font text
<b> Bold text </>
<h1> header is now <b> bold</></>
</font>
<script> Script text </script>
<h1> Another header is now <h> header embedded</></>
Body text
</body>
html ending
</html>
Output from scraper:
htmltext starting
Font text
Bold text
header is now bold
Script text
Another header is now header embedded
Body text
html ending
This is not linear text, the scraper will retain the skip and step links, unlike plain text which is a Comma separated only. So the 'stack' is preserved, it has all the plain text pointers back into the source in their original nested form. So join will be doing skip and step through the original web page plain text, and web authors know this. Authors will have a slight implicit grammar in their layout to take advantage of structure in the join.
Now the stack of pointers into the original source is an index in a graph database. . The attachment treats the two as a skip and step base of plain text interspersed with ignored text. Applications can allow users to browse via skip and text, external to html formatting. Users skip through plaintext groups, in each group key words highlighted, and user can select different key word lists at will. Extremely efficient news and information gathering for the busy executive.
Join is inherently extremely smart, or as smart as the word lists are selective. Pruned, efficient word lists will be big industry, the bots reviving the written word.
This is not linear text, the scraper will retain the skip and step links, unlike plain text which is a Comma separated only. So the 'stack' is preserved, it has all the plain text pointers back into the source in their original nested form. So join will be doing skip and step through the original web page plain text, and web authors know this. Authors will have a slight implicit grammar in their layout to take advantage of structure in the join.
Now the stack of pointers into the original source is an index in a graph database. . The attachment treats the two as a skip and step base of plain text interspersed with ignored text. Applications can allow users to browse via skip and text, external to html formatting. Users skip through plaintext groups, in each group key words highlighted, and user can select different key word lists at will. Extremely efficient news and information gathering for the busy executive.
Join is inherently extremely smart, or as smart as the word lists are selective. Pruned, efficient word lists will be big industry, the bots reviving the written word.
On what basis?
Mueller May Have Subpoenaed Trump Already
The evidence is clear, Trump really knew nothing, not that he didn't try. Maybe Muleskinner is going after his hotel business?
The evidence is clear, Trump really knew nothing, not that he didn't try. Maybe Muleskinner is going after his hotel business?
Janet!
The United States is taking on too much debt right now, a problem that is will only worsen moving forward, former Federal Reserve Chair Janet Yellen said Tuesday."If I had a magic wand, I would raise taxes and cut retirement spending," Yellen told CNBC's Steve Liesman at the Charles Schwab Impact conference in Washington, D.C., who characterized the U.S. debt path as "unsustainable."The U.S. fiscal deficit rose to $779 billion in fiscal 2018, up 17 percent from the previous fiscal year. This happened after President Donald Trump signed a bill late last year slashing the corporate tax rate to 21 percent from 35 percent. Spending levels climbed to their highest in six years while revenue only increased slightly.
Crowding out, they call it.
Bots create their own word lists
If they know a group of pages are related, or even not, the bot will cross reference the one with the other, many tomes over many pages and collect the common matches, pairwise, The common matches are word lists. With a bit of work the bot can find segmentation of web pages into groups, by adjusting wordlist to magnify compactness of page sets. A lot of NSA style mass processing of data, and the learning process is like neural nets with word lists at the nodes. Matching new words change lists; over time, the pit boss runs through the directed graph of lists, and prunes words off while adding new. Like a high speed, automated Webster.
Anybody can have a bot reader, all the mechanics make sense, and I am sure the mathematicians are on the job here to prove convergence.
Anybody can have a bot reader, all the mechanics make sense, and I am sure the mathematicians are on the job here to prove convergence.
The attachment plot for the web
If I look through the stack of resolved tags, in the order collected, the pointers back to the source retain the graph structure, the parts f it where from the text came. So, the join will step and skip through a web page. This is a great advance for the search strings, they can specify general to specific ordering.
Any application that wants to step and skip through the plain text web sites can do so. Only a few lines of code, after the stack of tags is resolved, step and skipm are managed by the residual pointers.
For a lot of web sites this is great, they know the customers is reading by blocks, left to right, top to bottom. They learn how to block their text, learn hos to share word lists, under the cover, with user search applications.
Any application that wants to step and skip through the plain text web sites can do so. Only a few lines of code, after the stack of tags is resolved, step and skipm are managed by the residual pointers.
For a lot of web sites this is great, they know the customers is reading by blocks, left to right, top to bottom. They learn how to block their text, learn hos to share word lists, under the cover, with user search applications.
Automated reading, no joke
If the target only has a vocabulary of 500 significant words, not problem, this machine can read web pages and find a reordering of the 500 words to represent the main idea of any web page. The power comes from high speed efficient cross listings, and the ability for it to choose from hundreds of lists dynamically. It can boil things down the effect being more reading by humans, the more humans can read the bots, the more secure they feel about the unexpected.
Bot speak
Plain text words, plus Dots, Commas, and Parenth pair.
Pick the world list with significance, especially if they are industry standard. Any computer and talk to any computer, and get it almost always right with plain text. The grammar is simple, there is in fact no other representation that allows serialization in one direction.
So, let us dump the complex interfaces, take a good guess, send it in plain text, become a graph of plain text. We can't go wrong because we can always be strict and controlled in the text selection, or not
Make the join universally available, everyone will get it, bots talk plain text.
Bots can teach your children to read. The cross referencing of word lists is high speed, and with a bit of an add on tool, the join can talk to you children, in plain text. Words significant, but not bottled up in punctuation. Easy for parents and teachers to create personalized word list for each child.
And, in bold letters:
Produce the children's key board, dump all the keys except 26 letters (and three ops, dot,comma,parenth), enlarge the keys Do not worry about caps, Type in, big text, join will figure it out. Entire industry of word list creators have a great new tool.
The scraper got slimmed and grimmed. I posted a new, untested copy. Still some slimming to do. I have seen it work on very complex interfaces, like Marginal Revolution, or any blog. It works exactly, you end upo with all the plain text you see on the screen, in proper order. In my case, there are stll a bug or two. That is a whole, a cmplete package for very few lines of code, easy to manage. Always have a scrape handy, feed it plain text URLs, and any interesting word lists you may have. Easy to make this develop a common word lost, and agreement between you and your bots. Plain text, a thumbprint; they do your shopping.
Pick the world list with significance, especially if they are industry standard. Any computer and talk to any computer, and get it almost always right with plain text. The grammar is simple, there is in fact no other representation that allows serialization in one direction.
So, let us dump the complex interfaces, take a good guess, send it in plain text, become a graph of plain text. We can't go wrong because we can always be strict and controlled in the text selection, or not
Make the join universally available, everyone will get it, bots talk plain text.
Bots can teach your children to read. The cross referencing of word lists is high speed, and with a bit of an add on tool, the join can talk to you children, in plain text. Words significant, but not bottled up in punctuation. Easy for parents and teachers to create personalized word list for each child.
And, in bold letters:
Produce the children's key board, dump all the keys except 26 letters (and three ops, dot,comma,parenth), enlarge the keys Do not worry about caps, Type in, big text, join will figure it out. Entire industry of word list creators have a great new tool.
The scraper got slimmed and grimmed. I posted a new, untested copy. Still some slimming to do. I have seen it work on very complex interfaces, like Marginal Revolution, or any blog. It works exactly, you end upo with all the plain text you see on the screen, in proper order. In my case, there are stll a bug or two. That is a whole, a cmplete package for very few lines of code, easy to manage. Always have a scrape handy, feed it plain text URLs, and any interesting word lists you may have. Easy to make this develop a common word lost, and agreement between you and your bots. Plain text, a thumbprint; they do your shopping.
Tuesday, October 30, 2018
My text scraper works fine on large html files
I can take professional web pages and run them through the text scraper, works fine. One bug, I have not yet implemented the singleton tags, so it generates the occasional error message. The extracted text is exactly the text observed. And I c an group the text a bit according tp the tag that marfked the text.
So I will go ahead and connect this to the join system. This ism hpw bots read web pages, no need for all that formatting, just sort of group the plain text. The bots will want a scraper and join machine in every server.
Other than singletons, I have not yet done escaped characters. Working, minus two minus deficiencies soon to be fixed.
So I will go ahead and connect this to the join system. This ism hpw bots read web pages, no need for all that formatting, just sort of group the plain text. The bots will want a scraper and join machine in every server.
Other than singletons, I have not yet done escaped characters. Working, minus two minus deficiencies soon to be fixed.
Illinois!
Republicans and Democrats had rotated in and out of the governor’s mansion in the capital of Springfield for 40 years without much change in the way the state was governed. A lot of them were crooks—four of Rauner’s nine predecessors, including Ryan, went to jail. Alone among recent governors, Rauner ran as a radical: a reformer who promised to upend, in fact to reverse, the way his predecessors had governed the state. Staying out of jail would be a bonus.And property taxes exceed mortgage payments for many. Newmark has the goods.
Bottlenecked, one cannot leave now without taking a big hit on home sales price, no one wants to move in.
Web scraper now working
I posted it to the right. There is some spaghetti, but it works, untested on large complex files, however. That is next. It came in at 200 lines of code, no headers all one file. Works from a filename. Some of the spaghetti can be optimized away, I am not worried. Most of the spaghetti is all about finding those tags.
I be testing it on ever larger files in a while. Here is the test file:
<html>
htmltext starting
<body>
<font> Font text
<b> Bold text </b>
<h1> header is now <b> bold</b></h1>
</font>
<script> Script text to be ignored</script>
<h1> Another header is now <h> header embedded</></>
Body text
</body>
html ending
</html>
Simple but include beginning and trailing text and skipped text and nested html blocks. It return all the correct text. I notice that my noetpad++ performs the same trick on html files, identifying plain text and bolding ii while keep script text unbolded. So I am not the first, and we prove, you do not need a full html parser to extract the plain text.
You do not actually need the tag identified in the closing "/>.", although browsers may require it. My system assumes a consistent html grammar and there is no need to identify which closing tag belongs to which opening tag.
I be testing it on ever larger files in a while. Here is the test file:
<html>
htmltext starting
<body>
<font> Font text
<b> Bold text </b>
<h1> header is now <b> bold</b></h1>
</font>
<script> Script text to be ignored</script>
<h1> Another header is now <h> header embedded</></>
Body text
</body>
html ending
</html>
Simple but include beginning and trailing text and skipped text and nested html blocks. It return all the correct text. I notice that my noetpad++ performs the same trick on html files, identifying plain text and bolding ii while keep script text unbolded. So I am not the first, and we prove, you do not need a full html parser to extract the plain text.
You do not actually need the tag identified in the closing "/>.", although browsers may require it. My system assumes a consistent html grammar and there is no need to identify which closing tag belongs to which opening tag.
Simple loop, final
My html web extractor. (updated)
All it needs to do is recurse through the html tree and mark selected tags as plain text. Plain text is what is left after all the open and close sequences have been resolved to either skipped tags or a string of plain text in the original source. The hard part is the spaghetti of crawling through HTML and finding tags.
The plan is to have an independent utility that grabs web pages and puts them to disk. Then, asynchronously, scraper attaches to join and will refine the pages from gibberish to the main idea, like Watson.
All it needs to do is recurse through the html tree and mark selected tags as plain text. Plain text is what is left after all the open and close sequences have been resolved to either skipped tags or a string of plain text in the original source. The hard part is the spaghetti of crawling through HTML and finding tags.
The plan is to have an independent utility that grabs web pages and puts them to disk. Then, asynchronously, scraper attaches to join and will refine the pages from gibberish to the main idea, like Watson.
int process_block(int in) {
int i=0;
Tag t;
int code;
if((in+2) >= intodex)
return(1); // doxe
PStack ptr = stack+in;
t= *(ptr->id); // debug look
//
// process all blocks in sequence until parent close
// We just need to mark the residual text
do {
if(Open(ptr+2)) // Peek beyond this close tag
process_block(in+2); // descend into next block
// Now at this point, until parent close,
// everything is Singleton, skip, or text.
code=(ptr+1)->code; // save origal code
if(ptr->code == Singleton) ptr++; // Singletons ignored
else if(ptr->code != Skip) {// Text is what left after most is filtered away
ptr->code = Text;
ptr++;
ptr->code =Text;
ptr++;
}
if(code == Close) //Parent is closed
return(0);
} while(1);
return(1);
}
Monday, October 29, 2018
my text scraper, main loop
My simple loop for web pages. It is built on the Tag protocol, each tag has a unique identifier, and ope and closing tags ae present, except for singletons. But I code the tags I wan in a static table, the unwanted 'blocks' are ignored. I don't build a tree, the grammar too simple.
First, I find all tags, open and closing and singletons, in order of appearance and push them onto a stack. The tag hold a point back into the original web page, and holds a pointer to the code book describing the tag.
The grammar is simple, If my stack has an opening tag followed by a closing tag, then there is no embedded trags, just plain text, or plain unwanted script. So I mark those tags as text, and they are passed over by the parent block, then exit, this is a leave. (note this code is untested). If thet ar disallowed text, like script, then it is marked as singleton.
In any even, I recurse back to the same call unless this is the end of the page. When done, my stack of tags have all been converted into either singletons or text. I can step though the stack and gather the text using the pointers back into the page, I have a database. I can even take a stab at some simple html grammar, maybe collect headers at their proper level, presenting some text as a tree.
This is standard parsing, by the way.
First, I find all tags, open and closing and singletons, in order of appearance and push them onto a stack. The tag hold a point back into the original web page, and holds a pointer to the code book describing the tag.
The grammar is simple, If my stack has an opening tag followed by a closing tag, then there is no embedded trags, just plain text, or plain unwanted script. So I mark those tags as text, and they are passed over by the parent block, then exit, this is a leave. (note this code is untested). If thet ar disallowed text, like script, then it is marked as singleton.
In any even, I recurse back to the same call unless this is the end of the page. When done, my stack of tags have all been converted into either singletons or text. I can step though the stack and gather the text using the pointers back into the page, I have a database. I can even take a stab at some simple html grammar, maybe collect headers at their proper level, presenting some text as a tree.
This is standard parsing, by the way.
int process_block(PStack ptr) {
int i=0;
PStack
Tag * s;
PStack endptr;
s = beginptr->tagid;
if(*s->name = 0)
return(i); // end of page
if(s->code == Singleton || s->code== Plaintext){ // Just step through
beginptr++;
process_stack_block(open_ptr);// skip one element
}
else {
endptr=inptr+1;
if(endptr->id->code == Close) // If no embedded blocks?
if(s->code== Emit) {// emit residual texttext atom
beginptr->is = &Text;
endptr->id=&Text;
}
else{
beginptr->is = &Single;
endptr->id=&Singleton;
}
process_block(endptr+1); // descend ustart of next block
}
return(i);
}
My text scraper
I wrote a quick one.
Like I say, find all tags an push them in the order found. Then sort the stack into a B-tree, the wae a parser would, or the way we do Huffman. But, a big but, I am pruning big sections of that tree as we go along, it shrinks down to a string of residual test. I dump format, script, tad 'onclick' type tags.
The text scraping job is to toss the mechanics stuff dealing with browsers, which is almost all of the document tree. So, I have a stack of sequence start and stops, nested, a compact graph. From stack bottom working up I find the first enclosed sequence and split the stack into two children, Except I am tossing more than half of the sequences discovered. My B-Tree decomposes to rank zero and I am left with a string of residual text, with big gaps; text from lists, title, body, headers, meta words.
The plain text words, in approximately the order appearing in the document. Then I can be working that plain text with a myriad of cross referencing word lists. Best search engine available, I should start a company. Send me ten bucks and I will send you one long c source file, load it into any directory, do no special set up, just type:
gcc onebigfile.c.
CutnPaste is the likely software distribution method, informally.
The text scraper will attach to the join, the web text scraper. Run two inputs, a LazyJ search and control graph and the web scraping attachment which treats the web like a directed graph of URL addresses. I reuse the dot sequence for URL: site.subsit.subsite, except I have the comma operator and distributed property, so in Lazy J I have:
LazyJ: masterSite.(Subsite2,Subsite2.Subsubit1,subsite3);
TextScrapper sees the grammar as a series of fetch, step and skip from the join machine. and returns the residual text for each page in graph order according to join grammar. From there I stack on a series of conditional joins with my myriad of word lists. It is all quite simple, anyone can do it; have a personal Watson.
And make money. Experts in a field have word lists in their head and texts, hey justm
need to organize them a bit, from general to specific, like a directed. The develop sets of joining word lists needed to make an intelligent robot in their field.
The text scraping job is to toss the mechanics stuff dealing with browsers, which is almost all of the document tree. So, I have a stack of sequence start and stops, nested, a compact graph. From stack bottom working up I find the first enclosed sequence and split the stack into two children, Except I am tossing more than half of the sequences discovered. My B-Tree decomposes to rank zero and I am left with a string of residual text, with big gaps; text from lists, title, body, headers, meta words.
The plain text words, in approximately the order appearing in the document. Then I can be working that plain text with a myriad of cross referencing word lists. Best search engine available, I should start a company. Send me ten bucks and I will send you one long c source file, load it into any directory, do no special set up, just type:
gcc onebigfile.c.
CutnPaste is the likely software distribution method, informally.
The text scraper will attach to the join, the web text scraper. Run two inputs, a LazyJ search and control graph and the web scraping attachment which treats the web like a directed graph of URL addresses. I reuse the dot sequence for URL: site.subsit.subsite, except I have the comma operator and distributed property, so in Lazy J I have:
LazyJ: masterSite.(Subsite2,Subsite2.Subsubit1,subsite3);
TextScrapper sees the grammar as a series of fetch, step and skip from the join machine. and returns the residual text for each page in graph order according to join grammar. From there I stack on a series of conditional joins with my myriad of word lists. It is all quite simple, anyone can do it; have a personal Watson.
And make money. Experts in a field have word lists in their head and texts, hey justm
need to organize them a bit, from general to specific, like a directed. The develop sets of joining word lists needed to make an intelligent robot in their field.
So I made the text scraper
For html pages my text extraction tool finds all the tag markers, beginning and end, and pushes them onto the stack as they are found, with pointers to their location. The stack becomes the exact schematic of the source document, it retains the nested structure.
Then I pull out the tags and look up the rule for that tag, which can be, 1) This is atomic text, emit the contents. 2) This has no text, skip ahead past the closing tag, and 3) This might have text, step into the enclosed html. Notice I am back to step, skip, or singleton.
My theory say I can easily find the text with some obvious rules, and a bit of missed text. I do not need the full html parser.
Then I pull out the tags and look up the rule for that tag, which can be, 1) This is atomic text, emit the contents. 2) This has no text, skip ahead past the closing tag, and 3) This might have text, step into the enclosed html. Notice I am back to step, skip, or singleton.
My theory say I can easily find the text with some obvious rules, and a bit of missed text. I do not need the full html parser.
A simple text scraper for html
A simple recursive algorithm to scrape plain text without the html parser. Descend the html document recursivelly on a tag by tag basis. Work from a table of tags having acceptable text, and either dump the tag of emit the tag contents. The whole key is identifying the begin an end tags, a simple state machine. The simplification is that we dump part most of the document tree before attempting to build an tree, just emit the text on a terminal node
So, the rule book says ignore <div> pairs. You just dumped a bunch of document structure, but that structure had little to do with plain text content. For each tag pair, the choices are, descend into into, dump it, or emt its text. 85% of the document is display boiler plate, needed in the walled garden environment. We can tag some emitted text, as from a header, for classification purposes, but otherwise most useful information in in the plan text, the word significance and order of appearance.
I might think about that, and search the web a bit, a simple, text extractor.
So, the rule book says ignore <div> pairs. You just dumped a bunch of document structure, but that structure had little to do with plain text content. For each tag pair, the choices are, descend into into, dump it, or emt its text. 85% of the document is display boiler plate, needed in the walled garden environment. We can tag some emitted text, as from a header, for classification purposes, but otherwise most useful information in in the plan text, the word significance and order of appearance.
I might think about that, and search the web a bit, a simple, text extractor.
I can keep statistics in my Huffman tree
This is basically scaling and truncing, but te floating point, the remainder, carriers on in the eighted price, and min max at each node. These nodes are bins, and any new trade leaving or old trade departing can traverse the treee and adjust counts, rebalancing as needed.
As long as I scale and truncate to match the market scale, then the technique is timeless, needing only the large sample over the complete sequence under analysis. Do this on an hourly basis, over the day. Weekly or quarterly, make sure you pick a known cycle, known in that you know it..
The tree is searchable, a reader can find the mostly likely trade deal at the current market uncertainty. A Huffman tree is how the pit boss should structure the bid an ask, separately. The tree has forensic capability, imbalances out of place show up, unusual arbitrage moments.. Queues in and out easily micro priced. Easy to use automatic watch dogs looking for mis-shappen tree, ready to pull the alarm.
As long as I scale and truncate to match the market scale, then the technique is timeless, needing only the large sample over the complete sequence under analysis. Do this on an hourly basis, over the day. Weekly or quarterly, make sure you pick a known cycle, known in that you know it..
The tree is searchable, a reader can find the mostly likely trade deal at the current market uncertainty. A Huffman tree is how the pit boss should structure the bid an ask, separately. The tree has forensic capability, imbalances out of place show up, unusual arbitrage moments.. Queues in and out easily micro priced. Easy to use automatic watch dogs looking for mis-shappen tree, ready to pull the alarm.
Sunday, October 28, 2018
My ideal GUI
A simple graphics engine in WASM for the bowsers.
It has mainly the sixteen basic graphic APIs to create window and draw, including capture a basic mouse click. Nothing mare, make it the official marketing policy, no boloat. Down load the WASM, single graphics module and run with the include script method.
It has mainly the sixteen basic graphic APIs to create window and draw, including capture a basic mouse click. Nothing mare, make it the official marketing policy, no boloat. Down load the WASM, single graphics module and run with the include script method.
The SP500 from 1950 1968

If we looked at values around the trend we see they are evenly dispersed. The trend is strong, so, relative to trend this series has about as many numbers around 30 as it does around 80. Around the point of symmetry we get a uniform distribution.
The deviations from trend show up as rare prices, (this is all aggregate opening price). We expect longer queues when rare events happen.
This is a bad choice to study, it has no complete set boundaries, so the data is aliased. But I made a Huffman tree out of it using three decimal precision:
100
36 64
16 20 32 32
8 8 8 12 16 16 16 16
4 4 4 4 4 4 5 7 8 8 8 8 8 8 8 8
2 2 2 2 2 2 2 2 2 2 2 2 2 3 3 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4
1111 1111 1111 1111 12 22 2222 2222 2222 2222 2222 2222 2222 2222
1 1111 1111 1111 1111 1111 1111
This is somewhat balanced, but the shortest path from root to leave ois 4 steps, the longest 7. Rare mevens have longer paths. There is more that we can do, this is just one tiny proof of concept. Mainly we want total wealth moved in the market, volume and prove. The other thing to remember, the market is efficient, already 'encoded' for efficiency.Huffman coding is a standard non lossy compression method for text. I can make it a bit lossy, do not do the exact match on words, see if they are in the special set of words Then my longest path represents the rare words needing multiple filters to identify, each node having a word filter, a word list of some exactness with which to join. That way we identify the structure of a text body much like we diagram a sentence.
My simple Ncurses
50 lines of code, three APIs. init_screen, int_to_str, put_screen.
The rule is, do not put any \n or \0 in the screen buffer, it is initialized to space. Printable, single char width only.
I can do all the character graphics I want, someone else can make it official and deal with the code bloat of modern GUIs. I can make tables and trees. I never have to screw with utilities that may or may not put in non printables while doing IO.. Best of all, easy to deploy using the old CutnPaste method for software configuration.
WASM fixes a lot of this graphics problem. WASM can deploy high speed graphics buffer routines, we will get much better browser applications. For researches then graphics in the browser is almost automatic, no hundreds of lines and thousands of APIs days to set up. In the lab, WASM will allow complete control of the browser screen with a simple set of draw utilities, almost like SDL for browsers.
Using my mini_curses with join.
Take the CONSOLE attachment, add the 50 lines of code and implement step and skip. Define key size for skip, the way MEM does it, but simpler. Output the screen buffer on Done. You have a database accessible by XY coordinates, but managed as a step and skip graph. Limited to printable key alphanum char key values, fix size text windows.
The rule is, do not put any \n or \0 in the screen buffer, it is initialized to space. Printable, single char width only.
I can do all the character graphics I want, someone else can make it official and deal with the code bloat of modern GUIs. I can make tables and trees. I never have to screw with utilities that may or may not put in non printables while doing IO.. Best of all, easy to deploy using the old CutnPaste method for software configuration.
WASM fixes a lot of this graphics problem. WASM can deploy high speed graphics buffer routines, we will get much better browser applications. For researches then graphics in the browser is almost automatic, no hundreds of lines and thousands of APIs days to set up. In the lab, WASM will allow complete control of the browser screen with a simple set of draw utilities, almost like SDL for browsers.
Using my mini_curses with join.
Take the CONSOLE attachment, add the 50 lines of code and implement step and skip. Define key size for skip, the way MEM does it, but simpler. Output the screen buffer on Done. You have a database accessible by XY coordinates, but managed as a step and skip graph. Limited to printable key alphanum char key values, fix size text windows.
Wow, linux is winning
IT'S OFFICIAL: IBM is acquiring software company Red Hat for $34 billion
OK, I am on board, Red Hat movs up in my list of a potential new OS/. Especially since they have MicroSoft Power Shell.
I am liking my broken system, a cheap lap top, it forces me to write simple algorithms, focus on fundamental algorithms. I suffer less code bloat.
OK, I am on board, Red Hat movs up in my list of a potential new OS/. Especially since they have MicroSoft Power Shell.
I am liking my broken system, a cheap lap top, it forces me to write simple algorithms, focus on fundamental algorithms. I suffer less code bloat.
Run time Huffman coding
The basic ide is to remove and add new queue elements onto the treem and slowly morph it. To do thios, take te item to be removed or added, and descend the tree ewith it, looking to see iof the new item is more rare than the nerxt to offspring. Also decrement or increent counts during the descent.
When the new element is more rre than the offspring, take the leasty likely of the two and pair it up with the new rentry, pair it up with the old entry removed, either way. But at that point in the tree, the algorithm recursers the sub graph and repeats the process,.
Yea, make for a great autobanker.
Here is the map for a uniform 8 bit random number. Notice it is balanced, no spectral pecularities. This method will detect imbalanced random number generators.
When the new element is more rre than the offspring, take the leasty likely of the two and pair it up with the new rentry, pair it up with the old entry removed, either way. But at that point in the tree, the algorithm recursers the sub graph and repeats the process,.
Yea, make for a great autobanker.
Here is the map for a uniform 8 bit random number. Notice it is balanced, no spectral pecularities. This method will detect imbalanced random number generators.
161
64 97
32 32 36 61
16 16 16 16 16 20 29 32
8 8 8 8 8 8 8 8 8 8 8 12 13 16 16 16
4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 6 6 6 7 8 8 8 8 8 8
2222 2222 2222 2222 2222 2222 2222 2222 2222 2222 2222 3333 3334 4444 4444 4444
1111 1111 1111 1111 1111 1111 1111 2 2222 2222 2222
1111 1111
Inverting, of finding the complement.
If the uniform tree is balance, then take an imbalanced tree and add the minimum branches to balance he tree. The adjoining sudb graph added should generate the unused quants, quants dumped due to compression.
Decode is to traverse down the tree, encode is up, if I have that right.
Stocks
The graph of the S&P500 will become suddenly asymmetric during a recession when the window is a full eight years. During the transition everything jams as the market resorts. When the market is stable then it changes like the run time encoder, a node at a time, adiaticaly. Not in a sudden downturn.
I will encode price times volume an get the total market money moved, month;y from this data. We cn see the graph change during recession.
Huffman trees
161
59 102
27 32 51 51
11 16 16 16
5 6 8 8 8 8 8 8
3 3 4 4 4 4 4 4 4 4
2222 2222
This tree is asymmetric, and low resolution. I can increase the resolution 10 and get the more balanced tree:
161
64 97
32 32 41 56
16 16 16 16 16 25 28 28
8 8 8 8 8 8 8 8 8 8 11 14
4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 5 6 7 7
2222 2222 2222 2222 2222 2222 2222 2222 2222 2333
1111 1111 1111 1111 1 11 1111 1111 1111 2
1
More balanced, high resolution. the function I am quantizing is tanh, by the way. let us increase the resolution another ten.:
161
64 97
32 32 36 61
16 16 16 16 16 20 29 32
8 8 8 8 8 8 8 8 8 8 8 12 14 15 16 16
4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 6 6 7 7 7 8 8 8 8 8
2222 2222 2222 2222 2222 2222 2222 2222 2222 2222 3333 34 44 4444 4444
1111 1111 1111 1111 1111 1111 1111 1111 1111 11 2 2 2222 2222
1 1111 1111
Much more balanced. The path length from root to leave is the rarity of the code. When most numbers have almost the same path then there is not much compression, their index is preserved almost everywhere preserved.Notice the total count is fixed, and this is an instability when increasing resolution, the graph will constantly requantize because the measurement more accurate than the data.
But, in an automatic S&L, the window sizes can be adjusted, causing either loans or deposits queues to differentiate from each other. The goal is to try and keep the tree mostly stable, and and allow imbalance, with the market making function making the two graphs homomorphic.. When the two are homomorphic then those n\count numbers should be in mostly a constant ratio across trees. Then the bot can apply interest charges by minimizing its market clear cost, bit error.
Increasing the resolution mens adding one more decimal digit of resolution, in this case. I am not limited to decimal or binary. I can scale the floating point numbers, fractionally, then convert to int.
Notice rank tends to increase as resolution increases. But these patterns, and dealing with them, is essential to the marginal autobanker.
Chart analysis is simple estimating this graph via geometry on the time series, but they are looking for changes in the bottlenecks. These tree isolate that data for them, they can see all the bottlenecks, spatially, at once; like watching a WalMart checkout. We can do it numerically.
Anything to do with join?
More than likely, yes. This is a tree, generated by the pit boss. The bot is a search graph, with little interface, the bot can treat the structured market queues as a simple 'step and skip' directed graph. The longer paths are the rare deals. This is what bots do.
I have a bunch of stock market data, again. In a few days I will bring it up and we can look at market structure, directly.
Simple graph display
/////// Make a B tree formatted 2-d onto a string
void descend(PNode o,int width, int line ,char* str) {
if(!o)
return;
int_str(str+width/2,o->count); // place value into string
descend(o->left,width/2,line,str+line);
descend(o->right,width/2,line,str+line+width/2);
}
And here is the outpu which displays ther count. Each parent totals its left and right siblings:
81
29 52
13 16 26 26
5 8 8 8
2 3 4 4 4 4 4 4
2
1 1
Simple enough, fill the string as if it were a console screen, then print it out line by line. I prefill a very long string with space. Then, given the line size, I can put exactly that many characters per line.
I wrote up a simple Huffman encoder, and I need to see the graph format, came up with this nifty plan. I am running values from the tanhm function into the huffman, and scaling, then truncating the value to see how well I can fine tune the tree encoding graph height and balance. Pit boss research.
My algorithm followed the Wiki description exactly. In the set of symbols input, I create a 'Node' for the symbol and the number of times used. The same symbol does not appear twice. That is where I scale and truncat floating pint values, I can adjust the coincidence frequency.
Once the values ae bubble sorted by count, then I can pop off the top new, least likely values, and pin them to a parent, which is pushed, and sorted. Each time I do this the stack size drops until iot is zero.
Then I need an easy visual, and just formatting a string as if it were a line by line console is simple. I like the idea of having a large string holding a prepared console output, line by line. I can get 80% of the visual I need with 5% of the set up and run.
Saturday, October 27, 2018
Web surfing with join
Simple enough, build a we build put and get attachment which can 'skip or step' through a hierarchy of http names. Do that with the search graph being a book mark graph, run the raw data to mem, then run that as input to plain text which emits standard comma separated word which you run though a stack of word lists for classification. The join I have should do that, except for a few remaining bugs.
Run this in the AM, and get the basic idea of all the latest financial news, then issue updates to your trading bots. What about sentence structure? Add standard dictionary to plain text then deliver 'set and step' the words in ordered graph, or at least deliver the word type in the proper order for further lexical analysis. Operationally, join should learn to read, develop nd prune word lists via training. The it can run, almost freely, against text of any distinct industry, tell you the nuts and bolts of the dailies.
Run this in the AM, and get the basic idea of all the latest financial news, then issue updates to your trading bots. What about sentence structure? Add standard dictionary to plain text then deliver 'set and step' the words in ordered graph, or at least deliver the word type in the proper order for further lexical analysis. Operationally, join should learn to read, develop nd prune word lists via training. The it can run, almost freely, against text of any distinct industry, tell you the nuts and bolts of the dailies.
WASM and python
Well matched, python can pre-compile into WASM, which is small, efficient and complete. At the pits, the standard python interpreter run the code, bot code can be held 'compiled' in a WASM, or WASM can be emitted by python compile. WASM and python likely hold the lead here, but different language formats built around exchange are being developed, all will be WASM compatible.
All the pits are adopting open sdt=interface standards, so the python code is fairly mobile, it can get up and go elsewhere, or dup itself; taking its money with it. This is what pure cash networking is all about. The bots can microprice there way around the net, the transaction costs trivial, why it becomes a singularity
All the pits are adopting open sdt=interface standards, so the python code is fairly mobile, it can get up and go elsewhere, or dup itself; taking its money with it. This is what pure cash networking is all about. The bots can microprice there way around the net, the transaction costs trivial, why it becomes a singularity
The Redneck Inc has a code of conduct
No one waits in line, except by choice.
Sort of the motto in all our wondrous technology.
Sort of the motto in all our wondrous technology.
Microsoft has me upgrading to Windows 10, maybe
Awfully tempting with the linux subsystem and power shell. I still liker Ubuntu, I am in no hurry until I finish my tax forms.
A lot of interesting things happening, like WAM mens we get full desktop application in out browser. The industry might go to a full sandbox condition for production work given the security problems WASM s
One can imagine a restricted simulator that keeps the bot code within the confined, finite boundary with known exits. If the simulator is secure, then bot code can be proofed, and allowed to roam. And, to make this even better, there is not likely going to be a special version that can outrun, not will any language outrun the WASM All of these inefficiencies removed from the web, then semantic networks and digital cash network are free to grow and prune.
For example, the join machine can have a 'check code' adapter. Parse the WASM to an inout, 'check code' into the other input, and collect boundary violations. Check failure to call their trusted miner, detect potential self harm in trades lost. Trading pros can capture their save rules in a grammar, and we check it join it against the bot codes. This is the future of computing\, it is what the bots understand.
How would we automate the bot checker again?
Well, in join, the output should be the trace of the matching path through both graphs. If the logi modifier is inverted, then is is the seyt of all unmatched paths. An unmatched node is one where the bot code is late to the trusted miner at risk. The 'bot checker' attachment can follow the trade path grammar in the simulator, as it happens via the join process, done in number of different methods, including artificial check points. Bot checker can tell when a trade sequence might take the user into the 'red zone' unexpectedly, or when it gets caught boucing between trades, an unmatch, collected on output which becomes the graph of all error possibilities.
A lot of interesting things happening, like WAM mens we get full desktop application in out browser. The industry might go to a full sandbox condition for production work given the security problems WASM s
One can imagine a restricted simulator that keeps the bot code within the confined, finite boundary with known exits. If the simulator is secure, then bot code can be proofed, and allowed to roam. And, to make this even better, there is not likely going to be a special version that can outrun, not will any language outrun the WASM All of these inefficiencies removed from the web, then semantic networks and digital cash network are free to grow and prune.
For example, the join machine can have a 'check code' adapter. Parse the WASM to an inout, 'check code' into the other input, and collect boundary violations. Check failure to call their trusted miner, detect potential self harm in trades lost. Trading pros can capture their save rules in a grammar, and we check it join it against the bot codes. This is the future of computing\, it is what the bots understand.
How would we automate the bot checker again?
Well, in join, the output should be the trace of the matching path through both graphs. If the logi modifier is inverted, then is is the seyt of all unmatched paths. An unmatched node is one where the bot code is late to the trusted miner at risk. The 'bot checker' attachment can follow the trade path grammar in the simulator, as it happens via the join process, done in number of different methods, including artificial check points. Bot checker can tell when a trade sequence might take the user into the 'red zone' unexpectedly, or when it gets caught boucing between trades, an unmatch, collected on output which becomes the graph of all error possibilities.
Central bank doing pure digiatl cash
As the Riksbank seeks to adapt to a society that is turning to cashless payment methods, the Swedish central bank is considering issuing a digital currency. While the bank explained a concept of an “e-krona” in a report last year, it said on Friday (October 26) that the currency should be designed to enable testing in the future, Fortune reported.“If the marginalisation of cash continues a digital krona, an e-krona, could ensure that the general public still has access to a state-guaranteed means of payment,” the Riksbank said. “Alternatively, not to act in the face of current developments and completely leave the payment market to private agents, will ultimately leave the general public entirely dependent on private payment solutions.”An experiment would include a “value-based e-krona,” which would enable traceable transactions. It would be stored in a mobile app or on a card. At the same time, the Riksbank called for proposals to legislative changes that could pave the way to providing legal standing to the e-krona.By traceable I think they mean no double spending. They must be talking to the crypto pros.
But this is pure, digital cash, just like the paper stuff; pass them around, your card will not double spend. The CBs have no choice, high speed robotic trading for us regular people is here to stay the central banks cannot deny us.
They make this error:
Sweden has fast become one of the most cashless societies in the world, which is seen as a potential problem for citizens without access to mobile phones or bank cards. In addition, there is worry about what would happen if the digital payments systems suddenly crashed.
The card has a watch battery, this is cash.
The merchant can use the company card. The terminal cn have battery backup. This is cash, no one is talking to the CB for verification, the two parties can verify the digital watermark, and both parties have the Smart, secure card functionality, and both parties have wireless com.
They got the castration anxieties

Linux subsystems for Windows is generally available on Windows 10
Along with Power Shell, Microsoft's competitor top bash. I wonder how the Unix community responds. Powershell seems to be the better shell program, but bash has not been updated, really, for years.
The net effect is that installations on linux systems is going to becomes very simple very soon.
The net effect is that installations on linux systems is going to becomes very simple very soon.
WASM is a particularly good idea
I been reading the docs, looking at the run time interpreter. This will be fast, and is all stack machine, like the old TI calculators, another push and pop machine.
The interpreter is small enough to fit onto a smart card, and the MASM itself can be easily proofed, it is safe enough to run inside the Browser sandbox. It is well d\one, and potentially could find its way into all sorts of trading bots. This is a savings for the smart card, there was an awful lot of javascript we would have other crammed into the thing. Instead we build a WASM model for honest accounting, needed for contract management. The new blockchain languages can be compiled into WASM.
The interpreter is small enough to fit onto a smart card, and the MASM itself can be easily proofed, it is safe enough to run inside the Browser sandbox. It is well d\one, and potentially could find its way into all sorts of trading bots. This is a savings for the smart card, there was an awful lot of javascript we would have other crammed into the thing. Instead we build a WASM model for honest accounting, needed for contract management. The new blockchain languages can be compiled into WASM.
Lawyer bot
This AI Startup Generates Legal Papers Without Lawyers, and Suggests a Ruling
And a bit of judge bot. I was wondering when this industry would be disrupted.
$200 billion a year in interest charges
For all the talk about health care this election season, politicians of both parties are ignoring a giant sucking sound.The cost of health care continues to soar, vacuuming up a growing share of the nation’s economic output and putting an ever-larger strain on both family incomes and government budgets. Since Medicare and Medicaid were created in 1965, the federal commitment to health care spending has grown from about 3 cents of every taxpayer dollar to nearly 34 cents, not counting interest payments on U.S. debt. And that share is set to keep rising in the coming years as the population ages.
Of the $600 billion in interest charges the federal government pays, a third of that are charges on past insurance payments for which we didn't have the taxes. We are borrowing money to pay for current medical services.
Large state voters don't care, do not understand. Large state budgets can cushion the blow. Small states do not have the economies of scale advantages. So when interest charges rise, as they have, small state senators will go on strike, we get a shutdown.
Trumpster and Saudis engage in a bit of genocide
Brutally Honest: Facebook Removes then Restores Images from Yemen
The images expose the blatant hypocrisy of the US in backing the corrupt Saudi Arabia regime in its war in Yemen.
It is odd that Israel would allow a defacto alliance with the Saudis after watching genocide in actions. This was mostly about arms sales and hotels.
Israel's problem is that given the ongoing genocide in Yemen makes us want to support Iran, and Iran plans no Trump hotels, so they get screwed.
The USA and Trump are fairly corrupt.
WASM!
Web Assembly bytecode is here, an interpretable assembly language for browsers.
The idea is that we can compile our c code into WASM, then load it onto a web page as script for execution. It is supposed tor 20 times faster than javascript. Solves a big problem and browser developers are on board.
The idea is that we can compile our c code into WASM, then load it onto a web page as script for execution. It is supposed tor 20 times faster than javascript. Solves a big problem and browser developers are on board.
WebAssembly is a new type of code that can be run in modern web browsers — it is a low-level assembly-like language with a compact binary format that runs with near-native performance and provides languages such as C/C++ with a compilation target so that they can run on the web
An unnecessary concept
Cloud Growth Slowdown Looms, Suggesting Tech Boom Near Peak
'Cloud' means not much, mostly a marketing term. Traversable semantic networks make sense, that is cloud. What the geeks currently call cloud is another name for client-server. There is nothing cloudy about it, just another server tech.
Traversable semantic networks are different, all robotic, all peer to peer, almost. The travelling bots have no idea if they are on a client or server, it all looks the same to them. N ot quite peer to peer as I found out in the join code, one side of the semantic network will have some dominance over the other. That is why we do research code, a quick way to see if there is a consistent grammar. IBM's Watson travels a cloud, it is crawling the semantic networks..
The staggering growth of cloud computing can’t go on forever. And reports from tech companies that make data-center hardware and sell the services suggest the industry’s expansion is cooling.
'Cloud' means not much, mostly a marketing term. Traversable semantic networks make sense, that is cloud. What the geeks currently call cloud is another name for client-server. There is nothing cloudy about it, just another server tech.
Traversable semantic networks are different, all robotic, all peer to peer, almost. The travelling bots have no idea if they are on a client or server, it all looks the same to them. N ot quite peer to peer as I found out in the join code, one side of the semantic network will have some dominance over the other. That is why we do research code, a quick way to see if there is a consistent grammar. IBM's Watson travels a cloud, it is crawling the semantic networks..
Friday, October 26, 2018
Integrated development environments
IDE they are called, the one I use is Virtual c, a teaching tool but is syntactically correct with c and works fine,
I tried QT Builder, too slow and they wanted me to learn about kits, Virtual c doesn't need kits.
I tried Code Blocks, except their screen had about a hundred buttons, including one for Fortran! Way too busy with all those buttons. It has some bugs.
Everyone wants to invent something new in their IDE and I would have to go search the web to learn about someone's wet dream.
C is simple, Virtual c is simple, the compiler is called simple c. When I want to create a project I just save the current set up as a project. Virtual C doesn't have bizarre project wizards needed to manage a bunch of file directories.
The IDEs become complicated because software geeks add a lot of complexity to the file layout and paths, none of which help in compiling or development. I find that in development, just put your include files right in with the source. Why screw around with a complex file layouts?
I tried QT Builder, too slow and they wanted me to learn about kits, Virtual c doesn't need kits.
I tried Code Blocks, except their screen had about a hundred buttons, including one for Fortran! Way too busy with all those buttons. It has some bugs.
Everyone wants to invent something new in their IDE and I would have to go search the web to learn about someone's wet dream.
C is simple, Virtual c is simple, the compiler is called simple c. When I want to create a project I just save the current set up as a project. Virtual C doesn't have bizarre project wizards needed to manage a bunch of file directories.
The IDEs become complicated because software geeks add a lot of complexity to the file layout and paths, none of which help in compiling or development. I find that in development, just put your include files right in with the source. Why screw around with a complex file layouts?
Linux is a nightmare on the desktop
The the idea that no single person is motivated to simplify the software. Everyone is loath to remove someone else's lines of code. So configuration shell operations have thousands of lines of code. The install instructions work about half the time relaqtive to the documentation.
That is not all, the console commands are as confusing as always, until you learn them. Playing around is not something one can do one the fly because the command words are made of clueless, vowel=less letters that give no hint of purpose. Complexity for complexity sake.
They use directories as information devices, capturing the lay out of the code by the structure of the include, lib, and bin, plus version so the install you get is like eight directories deep, Then sometimes you find every c source has its one header, so you end up with tens of header files which the developer never uses or sees, Three of four linuxm variation ojut ther, all of them try to simplify install by, bugt are never able to.
Once I have a working OS, I am loath to install because I know I will get more tons of crap or something will break. Microsoft is actually worse at making js load tons of crap, especially their veruses, the so called defenders that deletes.
It used to be simperl. The only thing that has changed is the internet, other than that, most of us to the same things on the PC that we did 20 years ago, with less crap.
A bit discouraging, I keep saying to myself, "I don;t remember all this complexity."
That is not all, the console commands are as confusing as always, until you learn them. Playing around is not something one can do one the fly because the command words are made of clueless, vowel=less letters that give no hint of purpose. Complexity for complexity sake.
They use directories as information devices, capturing the lay out of the code by the structure of the include, lib, and bin, plus version so the install you get is like eight directories deep, Then sometimes you find every c source has its one header, so you end up with tens of header files which the developer never uses or sees, Three of four linuxm variation ojut ther, all of them try to simplify install by, bugt are never able to.
Once I have a working OS, I am loath to install because I know I will get more tons of crap or something will break. Microsoft is actually worse at making js load tons of crap, especially their veruses, the so called defenders that deletes.
It used to be simperl. The only thing that has changed is the internet, other than that, most of us to the same things on the PC that we did 20 years ago, with less crap.
A bit discouraging, I keep saying to myself, "I don;t remember all this complexity."
About those growth numbers
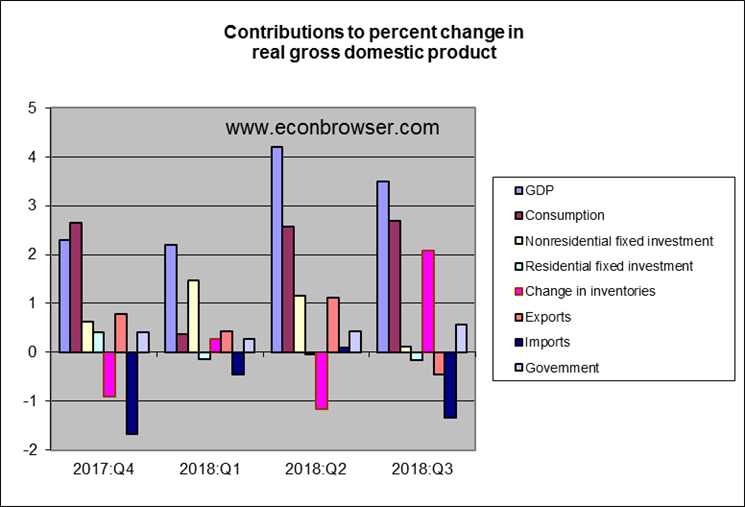
Most of the growth came from inventory build-up. GDP measures what is produced. If goods are produced but not purchased, inventories accumulate, so GDP can look strong even though spending is weak. Subtracting off inventories, real final sales were only up at a 1.4% annual rate in the third quarter.
Says James Hamilton.
The chart shows a big build up in inventory, not seen in previous quarters. He also mentioned that increases government spending accounted for .6 points of that growth number.
Can we sell the inventory at a profit? We shall see.
Microsoft has loaded my computer with viruses
They run around the computer deleting files they do not like. They have names like McAfee and Windows defender. The number of complaints about MS viruses is enormous, makes one wonder.
Only once have rogue viruses bothered me, but these official viruses from Microsoft are an enormous mistake for the company.
Linux has worse viruses. I was looking at 25,000 line shell command to install Ncurses, a simple character based GUI system. No way on need 25,000 lines of shell commands for anything. Linux is still a hieroglyphics nightmare. They create library directories galore, descend many steps into sub-cirstories for no apparent reason. And still have not yet discovered the vowel.
Software too cumbersome
The old days meant getting a copy of Win32.dll, and you could put up windows. The time to complete a hellom worlds by grabbing a copy of the dll was short, shorter than the time today when entire cloud systems get downloaded simply to write the hello world.
The browser with javascript eliminate bunch of that, and we can build applications to run in the browser. It is always the same, layers get big and complex; n then someone does it simple, like in the old days and a company is 'reborn', recycled.
SQLite is another, simpler is better, product. My Virtual c IDE is like that, built for simplicity, and simple layering.
QT, the multi-platform GUI tool has gotten way complex, as is SDLite, the direct layer graphics package. QT should be like win32.dll, have a QT.dll for graphis, one linkable file. If you want more complexity, start simple, and layer; but do not screw the simple, keep the basic, single file version for the simple stuff.
Only once have rogue viruses bothered me, but these official viruses from Microsoft are an enormous mistake for the company.
Linux has worse viruses. I was looking at 25,000 line shell command to install Ncurses, a simple character based GUI system. No way on need 25,000 lines of shell commands for anything. Linux is still a hieroglyphics nightmare. They create library directories galore, descend many steps into sub-cirstories for no apparent reason. And still have not yet discovered the vowel.
Software too cumbersome
The old days meant getting a copy of Win32.dll, and you could put up windows. The time to complete a hellom worlds by grabbing a copy of the dll was short, shorter than the time today when entire cloud systems get downloaded simply to write the hello world.
The browser with javascript eliminate bunch of that, and we can build applications to run in the browser. It is always the same, layers get big and complex; n then someone does it simple, like in the old days and a company is 'reborn', recycled.
SQLite is another, simpler is better, product. My Virtual c IDE is like that, built for simplicity, and simple layering.
QT, the multi-platform GUI tool has gotten way complex, as is SDLite, the direct layer graphics package. QT should be like win32.dll, have a QT.dll for graphis, one linkable file. If you want more complexity, start simple, and layer; but do not screw the simple, keep the basic, single file version for the simple stuff.
Thursday, October 25, 2018
Stealing from the poor, give to the rich
Stealing from millennials to give to the rich. Robinhood app sells user customer data to make a quick buck from the high-frequency trading (HFT) firms on Wall Street," that is what we wrote last month, in one of the first articles that expressed concern over the popular Robinhood investing app for millennials, which has shady ties to HFT firms and undermines its image of an anti-Wall Street ethos. Almost a month after our report, Bloomberg has now confirmed that more than 40% of Robinhood's revenues earlier this year were derived from selling its customers' orders to firms, like Citadel Securities and Two Sigma Securities.The cost of setting up trades is small, open banking API lowers the cost. So, why not give everyone the code? Why bother with a middleman like Robinhood?
Wednesday, October 24, 2018
Egads on the market
Quite the two three point dive. Mostly two things, emerging markets are recovering and rising rates flush the zombies.
My joins are stacking
The next step in test, was how well the instance stack work automatically. Works fine, after a few bug fixes. The memory exchange is working which is new stuff, two independent attachments automatically exchanging without any real knowledge of the one over the other.
I likely have one more nasty bug, but this version I have is complete, a version 1.0, production alpha, with a likely nasty bug. Soon I will update the blog files. Folks are free to invent their own graph syntax and invent new keys definition, having full control over match, still using join for classification purposes of raw key values.
They can add symbol table in their attachment, incl;udr nsm modifier opcodes, wildcard search functions.
My intention is to develop a word hierarchy, sets of words from general to specific. Then my app dynamically stack different word lists, marching down its own graph, trying to get the most specific match against the raw text. If my app is lost, it can invent the logic and collect the unmatched key words in raw text, getting itself learnt with a new classification and a cross reference words list. My app will be open source Watson, I like their approach, their machine can read, and everyone should have one.
I likely have one more nasty bug, but this version I have is complete, a version 1.0, production alpha, with a likely nasty bug. Soon I will update the blog files. Folks are free to invent their own graph syntax and invent new keys definition, having full control over match, still using join for classification purposes of raw key values.
They can add symbol table in their attachment, incl;udr nsm modifier opcodes, wildcard search functions.
My intention is to develop a word hierarchy, sets of words from general to specific. Then my app dynamically stack different word lists, marching down its own graph, trying to get the most specific match against the raw text. If my app is lost, it can invent the logic and collect the unmatched key words in raw text, getting itself learnt with a new classification and a cross reference words list. My app will be open source Watson, I like their approach, their machine can read, and everyone should have one.
PDF form problems are back
Our ability to save editable pdf from our Chrome browser has gone away. Some marketing ploy from giggle no doubt, editing pdf is a big ad revenue source for them.
But all the pdf s
Yes, folks should by software, but first, lets stop prodcing a proprietary format like PDF.services lie about it. They lie about a bunch of stuff related to pdf. Like they say you can save an editable pdf file until you read the fine print, you can fill our the form and save it once; or else buy an editor for $150. Once the IRS dumps pdf for oother optional formats, then great news for removing a big hassle with IRS forms.
Other problem. Turbo tax, all $200 of it replaces 8 lines of a spread sheet for most taxpayers. 90% of us fill in about ten lines on a 1040, any high school kid can do that on a spreadsheet. But once the high school kid did the spreadsheet, you have to get it onto a pdf form, and that part is a big, unnecessary hassle. Dump pdf.
But all the pdf s
Yes, folks should by software, but first, lets stop prodcing a proprietary format like PDF.services lie about it. They lie about a bunch of stuff related to pdf. Like they say you can save an editable pdf file until you read the fine print, you can fill our the form and save it once; or else buy an editor for $150. Once the IRS dumps pdf for oother optional formats, then great news for removing a big hassle with IRS forms.
Other problem. Turbo tax, all $200 of it replaces 8 lines of a spread sheet for most taxpayers. 90% of us fill in about ten lines on a 1040, any high school kid can do that on a spreadsheet. But once the high school kid did the spreadsheet, you have to get it onto a pdf form, and that part is a big, unnecessary hassle. Dump pdf.
Mostly a regulatory conflict
The problem remains unsolved of feeding a program with real-world data in a tamperproof way, or of running a currency peg without any risk to customers from dishonesty or incompetence by the party holding the reserves.
Larry White discussing the state of Bitcoin mentions this observation.
The emphasis is on tamper proof, really means no secure smart card, no reliable contract manager in the hands of the customer. Banks will trusted the secure, anonymous smart card, more specifically, banks will make cash in advance possible with smart card and pre-quals. Cash in advance is algorithmic and require adjustments of deposits to savings on an algorithmic basis.
But we have made it, we have a finger print sensor on a released credit card. Secure enough, the cash layer can remain on th server for now, but we can do cash in advance, algorithmically. Open banking implies that the credit card with print sensor is available to apps everywhere, an algorithmic S&L technology has already been deployed, in a fashion.
My prediction holds, 2018 is the first year of deployment, the complete sandbox chain in operation.
Monkeys and the race card came back
Roughly halfway through CNN’s Florida Governor’s Debate, Democratic nominee Andrew Gillum accused Republican Ron DeSantis of “doing all he can to draw attention to the color of my skin.”Gillum made the remark after CNN’s debate host, Jake Tapper, asked DeSantis to respond to Florida voters that, Tapper alleged, may have concerns about DeSantis’s “tolerance.” Tapper cited an on-air comment by DeSantis just a day after the primary in which DeSantis said off-handedly that voters shouldn’t “monkey this up” in reference to Florida’s booming economy.DeSantis flatly denied allegations of racism and cited his work as a military lawyer and prosecutor before Tapper allowed Gillum to respond.“The congressman let us know exactly where he was going to take this race the day after he won the nomination. The ‘monkey up’ comment said it all. And he has only continued over the course of his campaign to draw attention to the color of my skin.”Ever since Roseanne mentioned planet of the apes, monkeys have been in the news. Here is the new language:
- To monkey around. 'To monkey around' means to behave in a silly or careless way. ...
- To make a monkey out of someone. 'To make a monkey out of someone' means to make someone look silly. ...
- Monkey business. ...
- Monkey see, monkey do. ...
- Cheeky monkey. ...
- More fun than a barrel of monkeys. ...
- Monkey's uncle.
So, feel free to use monkey idioms, the Rednecks don;t care, it doesn't offend us, we come from mountain country, descended from bears. Just don't say we smell like a bear, even when we do.
Tuesday, October 23, 2018
Give them tent cities
US tech giants split over corporate tax to help homeless
They have nother problem, jackasses rule those central american nations, jackasses and gangs with the castration anxiety, so life is a real pain in the ass. Then add in the hurricanes.
All they want is camptown, the USA outta go down there and build camptown, lock the jackasses outside of the fence.
They have heard about the nice tent cities in Texas. Go help them build their own tent cities.
San Francisco (AFP) - Taxing San Francisco's wealthiest companies to rein in the city's homelessness problem makes sense to local campaigners -- but the local tech giants aren't all so sure.On November 6, voters in the city that is the home base of Twitter, Uber and Airbnb will decide the fate of "Proposition C," a local ballot measure brought about by a 28,000 signature petition this summer.Designed to rake in $250 to $300 million in taxes per year, the Robin Hood-esque measure would fund housing for 5,000 people and finance mental health and housing aid services, its backers say.
They have nother problem, jackasses rule those central american nations, jackasses and gangs with the castration anxiety, so life is a real pain in the ass. Then add in the hurricanes.
All they want is camptown, the USA outta go down there and build camptown, lock the jackasses outside of the fence.
Great idea
Societe Generale is testing the idea of issuing bank cards that incorporate a built-in fingerprint verification sensor with the aim of using the added security the cards provide to allow customers to make contactless payments “with no limit on the amount.”“Because the cardholder authenticates himself by means of his finger rather than entering the PIN code, all payments can be made using contactless with no limit on the amount,” the bank says.“Furthermore, the card functions normally for all contact-type payments in-store, on the internet or for withdrawals.“On receipt of the card the cardholder records his fingerprint himself in the biometric card,” the bank adds. “The fingerprint is verified directly on the card. No element linked to this fingerprint is transmitted to the merchant or to the bank.”Fingerprints validate trading bots working on our behalf.
Full working join chain
I can debug an app that is running raw text to memory. Insert the 'continue' statement and the app script drops down to consol executive, and from there I enter debug with access to everything, including special code to display structures.
I discover that the join system actually works, the matched keys get stored in structured memory, accessible as input in proper order/. I exit the debug back to the application and it runs the next round of scripts, sending memory to the console in structured order.
All of this with four or five script statements which just switch the flow between different triplet slots. I mathes fast, 3,000 character from text matched against a list of 20 words is a blink.
I can make it step on each pass through the loop but I figure that to be unnecessary. The loop is and remains staboe for a long time since the traversal bering simplest has an obvious optimum set of steps; a well solved problem..
I discover that the join system actually works, the matched keys get stored in structured memory, accessible as input in proper order/. I exit the debug back to the application and it runs the next round of scripts, sending memory to the console in structured order.
All of this with four or five script statements which just switch the flow between different triplet slots. I mathes fast, 3,000 character from text matched against a list of 20 words is a blink.
I can make it step on each pass through the loop but I figure that to be unnecessary. The loop is and remains staboe for a long time since the traversal bering simplest has an obvious optimum set of steps; a well solved problem..
Crashy like
October Auto Sales Tumble: "Our Car Sales Are Down 12 Percent"
This channel outta had been learnt well.
Likely at 12% drop is OK in their volatile world. But still, any sector reporting down more than 4% are scary, more than 10% seems crashy.
Bad year for pension funds
The market has no gains fn in 2018. The ten yer yields 3.2%, the public sector pension funds cannot even make 5% this year. Local government funding will be exhausted to make up the difference.
I still have back taxes to negotiate. I don;t want my IRS coiunterparty worrying about pensions.
I still have back taxes to negotiate. I don;t want my IRS coiunterparty worrying about pensions.
Simple debug for join, my first app
There is a 'continue' script for the command handler, it is just like "quit" but with a different exit code. When I debug script, I leave a continue after the first join. Then my return code tells the app to call console_loop. I can interrogate the stable state of the machine. When done, I enter "continue" and then script continues processing where it left off. I can only debug between joins.
I could define the debug mode, and the join operation will have one more test in the loop. At the bottom of the join loop it is perfectly reasonable, or should be, to call the console_loop(), and check the return for an abort or continue.
Debugging a stack of joins will be easier than we assume, especially given the native MEM format used, MEM almost always has the intermediate results, and can be examined intelligently.
I could define the debug mode, and the join operation will have one more test in the loop. At the bottom of the join loop it is perfectly reasonable, or should be, to call the console_loop(), and check the return for an abort or continue.
Debugging a stack of joins will be easier than we assume, especially given the native MEM format used, MEM almost always has the intermediate results, and can be examined intelligently.
Application format
Not much ode in the applicqtion interface. his one executes a scroipt then goes to interactive mode.
int exec_shell_command(char *);
int console_loop(void);
int main(void){
int i=0;
int count = sizeof(script)/sizeof(char *);
printf("%d %d\n",sizeof(script),count);
while(i < count) {
exec_shell_command(script[i]);
i++;
}
console_loop();
return 0;
The script is just static text I use for testing. Here is the example. I run the script in two parts or one part, each time join terminates and leaves the 'databes' attachments in a consistent state. So I can manually start up the second instance, taking output from the MEM structure already resident. Two external call here, one to the console loop and one to the executive with script. Very simple.<
static char* script[] = {
"list",
"set LAZYJ 0 json.txt 100",
"set TEXT 1 grammar1.txt 10000",
"set CONSOLE 2 20 2000",
"list",
"join"};
"dup 2,3",
"set CONSOLOE 5",
"set LAZYJ 4 join.txt",
"join" };
/pre>
<
Monday, October 22, 2018
I rearranged the code, likely for the last time
Applications, like a test applications needed to be simplified, so I built the slot system discussed earlier. The executive, console commands, knows about slots and cursors. Apps only know about setting up an managing slots. Apps send simple commands to the executive to control join. Good enough for my test applications, making it easy to run myriad of configurations and step through the miserable bugs.
Reading equities in join
We want a uniform presentation of a summary balance sheet for some variety of financial descriptions. Our search graph is just that, the definition of the normal form balance sheet and cash flow. Company financial information may be a bit scattered, but join learns the company, it sniffs through company text and develops key word list that help it organize financials.
So we have new text, unseen from the company. We let join sift through it using is collection of categorized word lists. Do this fast, I mean fast; bring all the world list, reat4 them automatically.
It can do feature detection if the feature hierarchy can be seen as directed graph, from general to specific. Feateurs mayber ber bit maps, match is adptd to find partial matches. Search for one or more close matches to known graphs. Math geeks know about which I speak. Handwriting analysis, finger print, image detection. The ability to stem roll though stacked layers of lists makes it work.
Anyplace you have big data, treat is as set classification by learning, and keep the hierarchy of canonical sets developed by learning. This machine is thinking.
String arguments
The application interface is dealing with am small list of integer indices indicating the slots the application occupies. There are about six things the application might do with slots, all of them needing only simple, short arguments.
So, dump the header file, only one entry is needed and the string argument list ultimately gets passed in as a variable argument list, it is parsed. It is a quick process and sending the join system short text message eliminates a lot of complexity.
It also means I am about done.
So, dump the header file, only one entry is needed and the string argument list ultimately gets passed in as a variable argument list, it is parsed. It is a quick process and sending the join system short text message eliminates a lot of complexity.
It also means I am about done.
Isolation of the application in join
Applications work with an integer index defining a slot in the stack of active join instances, the triple stack. They select the attachment, get an index onto the triple stack and their fine. Applications have a data object to be joined, they have to k ow about that, and so does the attachment.
Mainly the application needs to view the data as a structured branch and descend data structure, Dotted sequences of the Comma separated. The application is moving data results from slot to slot, while the attachment removes cursors after a Done, automatically. The application is free to throw different cross reference files at join, filling its empty slot, like a piping system, a message switch. A very powerful tool in all kinds of analysis, especially since the attachment controls the Match process and delivers data as needed. Every attachment sees the same data structure, key/op pair with an implied position in the graph. The sufficient and minimum information needed for the task.
The console commands are about slots, what is in them, what are the triples, feeding one slot to the other, and filling a slot. For example, when the application is satisfied, it has narrowed down the unknowns, then it can pipe tre results from MEM to CONSOLE, really by using a dup_slot, and new_slot calls. Then it can list slots, and list the attachments available. Application developers do not worry about join support, the rules of convolution are fairly obvious, and recreating join in various forms easy.
Pausing in stacked joins.This is one of the grammar rules, when should one triple puse? One strategy is to pause after ending a sequence, let the further triple digest that. The other is tpo pause when the a slot is empty or full. Whatever he default rule, the attachments can over ride the rule, pausing according to its own idiosyncrasies. The switch concept is asynchronous, one flow dependent upon another.
Typical application flow:
You hve a list of word list, in some hierarchical arrangement and you can intelligently cross reference you word lists with raw text, narrow it down. You end if with a bunch of if then.
If it matches well with list a then try list b,c,d and f; otherwise go try ;list X or Z and so on...
That is interpreted as filtering lists from slot to slot, a simple procedure for most applications, no worse than plumbing. Join puts the AI power in the hands of little folks. This idea will be on every computer.
Easy setup
Just have gthe console do a get string back from the application, then the application can deliver simple byte codes as needed to control join. Not even a header file: do_join_op(char*), in c will link in the application in., the application then then return command codes specifying actions. Type help art console and those are the command codes and format for standard attachens.
. The attachment needs to know more, it needs to know what a cursor is.
Mainly the application needs to view the data as a structured branch and descend data structure, Dotted sequences of the Comma separated. The application is moving data results from slot to slot, while the attachment removes cursors after a Done, automatically. The application is free to throw different cross reference files at join, filling its empty slot, like a piping system, a message switch. A very powerful tool in all kinds of analysis, especially since the attachment controls the Match process and delivers data as needed. Every attachment sees the same data structure, key/op pair with an implied position in the graph. The sufficient and minimum information needed for the task.
The console commands are about slots, what is in them, what are the triples, feeding one slot to the other, and filling a slot. For example, when the application is satisfied, it has narrowed down the unknowns, then it can pipe tre results from MEM to CONSOLE, really by using a dup_slot, and new_slot calls. Then it can list slots, and list the attachments available. Application developers do not worry about join support, the rules of convolution are fairly obvious, and recreating join in various forms easy.
Pausing in stacked joins.This is one of the grammar rules, when should one triple puse? One strategy is to pause after ending a sequence, let the further triple digest that. The other is tpo pause when the a slot is empty or full. Whatever he default rule, the attachments can over ride the rule, pausing according to its own idiosyncrasies. The switch concept is asynchronous, one flow dependent upon another.
Typical application flow:
You hve a list of word list, in some hierarchical arrangement and you can intelligently cross reference you word lists with raw text, narrow it down. You end if with a bunch of if then.
If it matches well with list a then try list b,c,d and f; otherwise go try ;list X or Z and so on...
That is interpreted as filtering lists from slot to slot, a simple procedure for most applications, no worse than plumbing. Join puts the AI power in the hands of little folks. This idea will be on every computer.
Easy setup
Just have gthe console do a get string back from the application, then the application can deliver simple byte codes as needed to control join. Not even a header file: do_join_op(char*), in c will link in the application in., the application then then return command codes specifying actions. Type help art console and those are the command codes and format for standard attachens.
. The attachment needs to know more, it needs to know what a cursor is.
Subscribe to:
Posts (Atom)